Learn about Claude Opus 4.6
The new Claude Opus 4.6 improves programming skills compared to its predecessor. It plans more carefully, maintains automated tasks for longer periods, can operate reliably in larger codebases, and has better code review and debugging skills to detect its own errors..
The new Claude Opus 4.6 improves programming skills compared to its predecessor. It plans more carefully, maintains automated tasks for longer periods, can operate reliably in larger codebases, and has better code review and debugging skills to detect its own errors. And, for the first time for Opus-class models, Opus 4.6 has a 1 million token context window in beta1.
Opus 4.6 can also apply its improved capabilities to a range of everyday work tasks: running financial analysis, research and development, and creating documents, spreadsheets, and presentations. In Cowork, where Claude can automatically multitask, Opus 4.6 uses all of these skills to support you.
In Claude Code , you can now assemble groups of agents to work together on tasks. On the API, Claude can use compression to summarize its own context and perform longer tasks without limitations. Claude is also introducing adaptive thinking, where the model can capture contextual clues about how much of its extended thinking is being used, and new effort controls to give developers more control over intelligence, speed, and cost.
The developers have also made significant upgrades to Claude in Excel, and will release Claude in PowerPoint in a research preview. This makes Claude much more useful for everyday work.
Claude Opus 4.6 is now available on Claude.ai, the API, and all major cloud platforms. If you are a developer, use Claude-opus-4-6 through the Claude API. The price remains unchanged at $5/$25 per million tokens.
First impression
Claude is built by itself. Engineers write code in Claude Code every day, and every new model is tested on its own work first. With Opus 4.6, the model focuses more on the most difficult parts of a task without needing guidance, handles simpler parts quickly, solves ambiguous problems with better judgment, and maintains productivity over longer work sessions.
Opus 4.6 typically thinks more deeply and reconsiders its reasoning more carefully before providing an answer. This produces better results for more complex problems, but can increase costs and delays for simpler problems. If you find that the model is overthinking a particular task, you should reduce the effort from the default (high) setting to medium. You can easily control this using the /effort parameter.
Claude Opus rating: 4.6
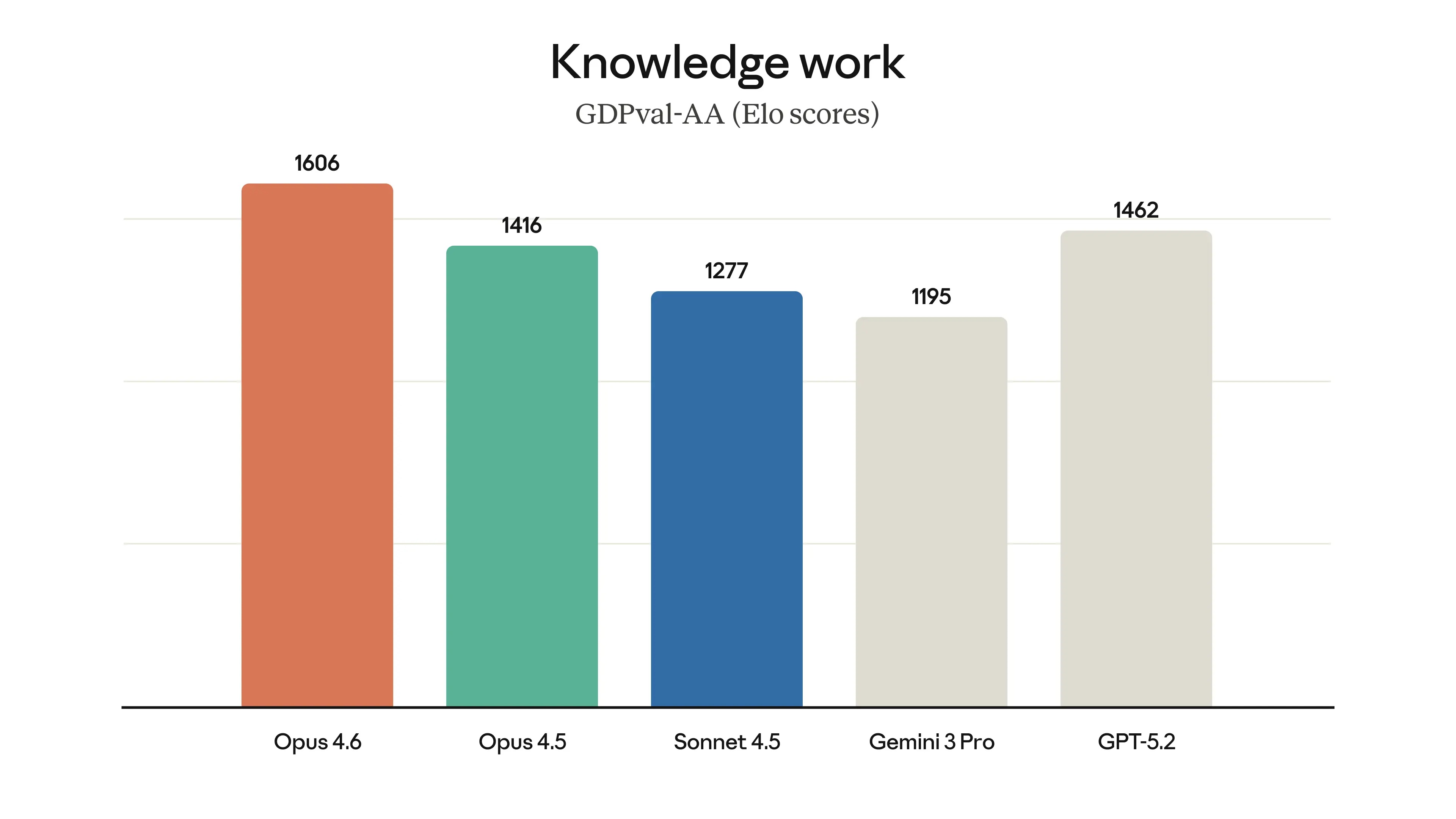
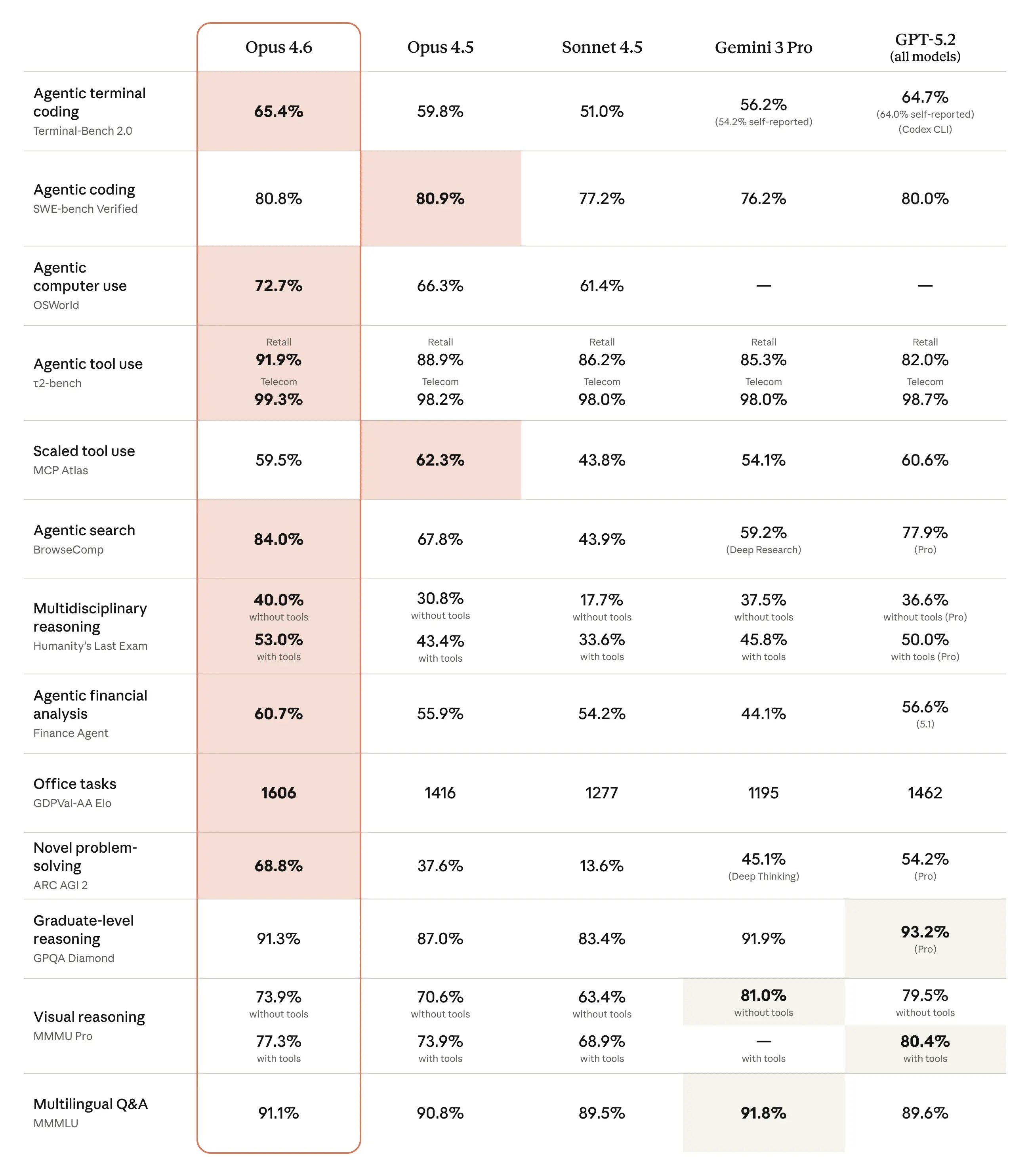
In areas such as agent programming, computer usage, tool usage, search, and finance, Opus 4.6 is a leading model in the industry, often outperforming others. The table below shows how Claude Opus 4.6 compares to previous models and other industry models across various evaluation criteria.
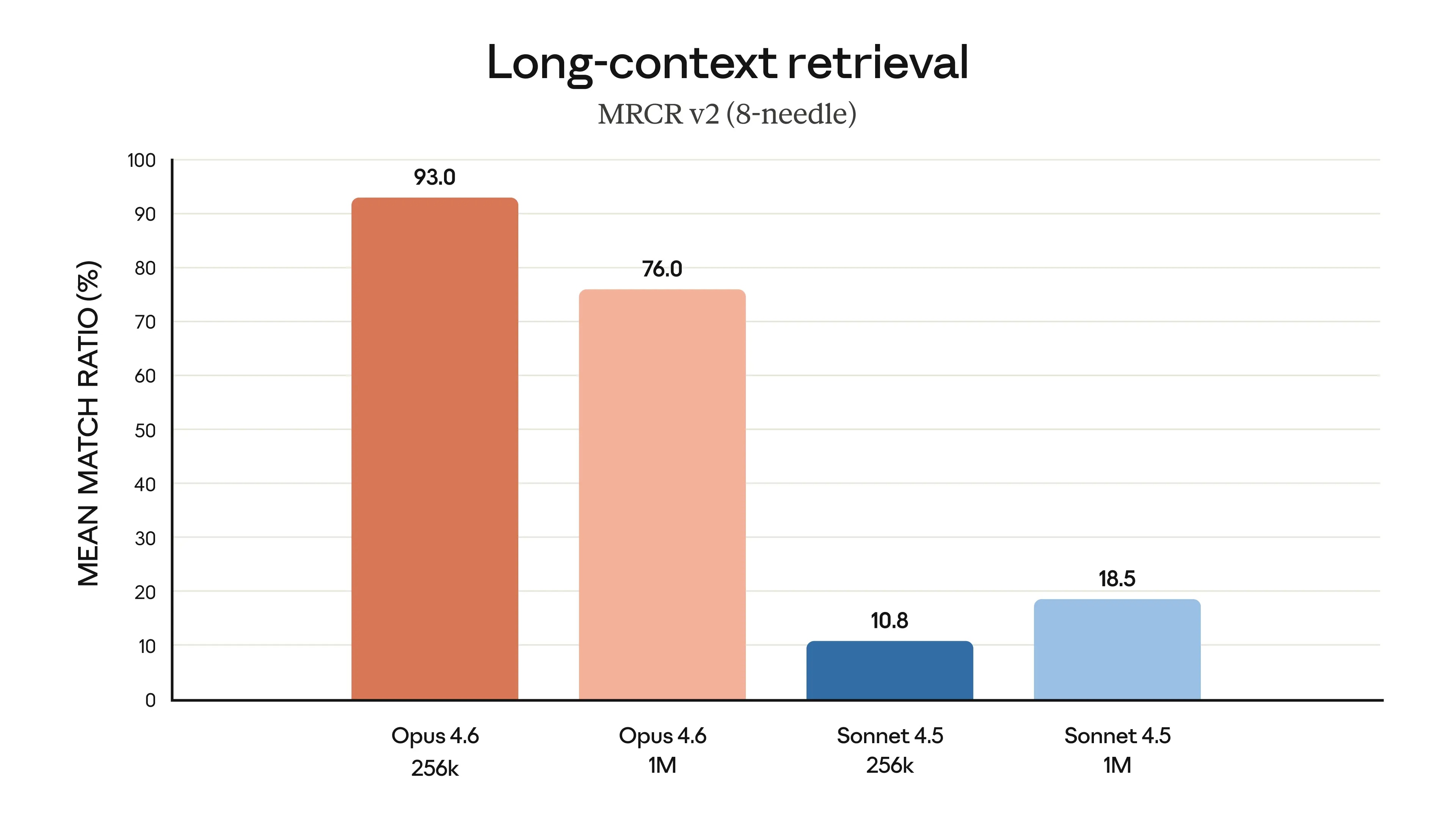
Opus 4.6 is far better at retrieving relevant information from large document sets. This extends to long-contextual tasks, where it stores and tracks information across hundreds of thousands of tokens with less deviation, and uncovers hidden details that even Opus 4.5 missed.
A common complaint about AI models is 'contextual degradation,' where performance declines when conversations exceed a certain word count. Opus 4.6 performs significantly better than previous versions: on the 8-pin 1M variant of MRCR v2 – a test of its ability to find 'hidden' information within large amounts of text – Opus 4.6 achieved 76%, while Sonnet 4.5 only reached 18.5%. This represents a qualitative shift in how much context a model can actually utilize while maintaining peak performance.
In summary, Opus 4.6 is better at retrieving information in longer contexts, better at reasoning after absorbing that information, and has significantly better expert-level reasoning capabilities overall.
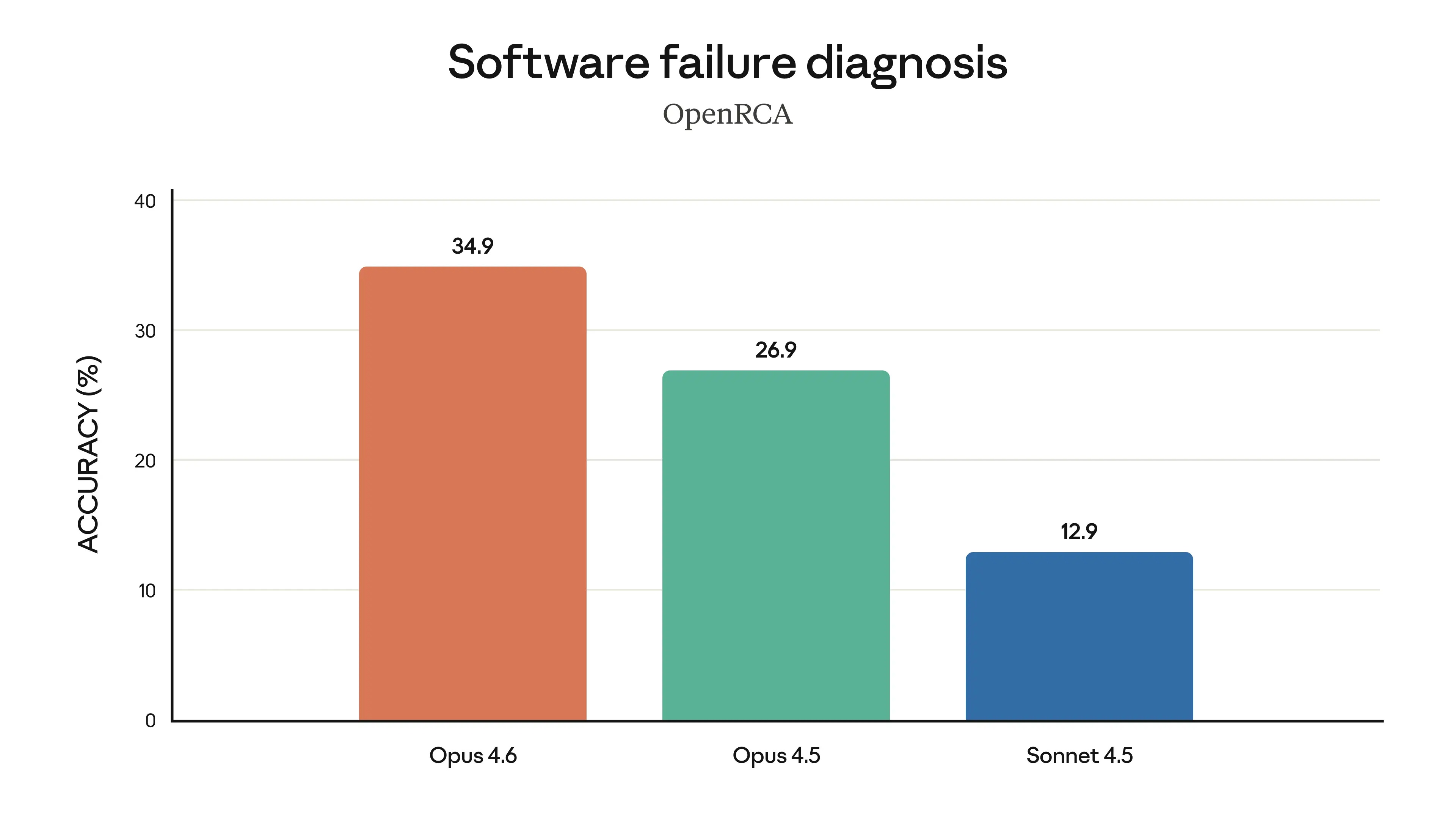
Finally, the charts below show the performance of Claude Opus 4.6 across various evaluation criteria, including Software Engineering skills, multilingual programming ability, long-term consistency, cybersecurity capabilities, and knowledge of life sciences.
A step forward in safety.
These advancements in intelligence do not come at the cost of safety. In automated behavior testing, Opus 4.6 showed low rates of inappropriate behavior, such as deception, flattery, encouraging user delusions, and cooperating with abuse. Overall, it matched as well as its predecessor, Claude Opus 4.5, which has been the most successful pioneering model to date. Opus 4.6 also showed the lowest over-rejection rate—where the model fails to respond to harmless queries—compared to any recent Claude model.
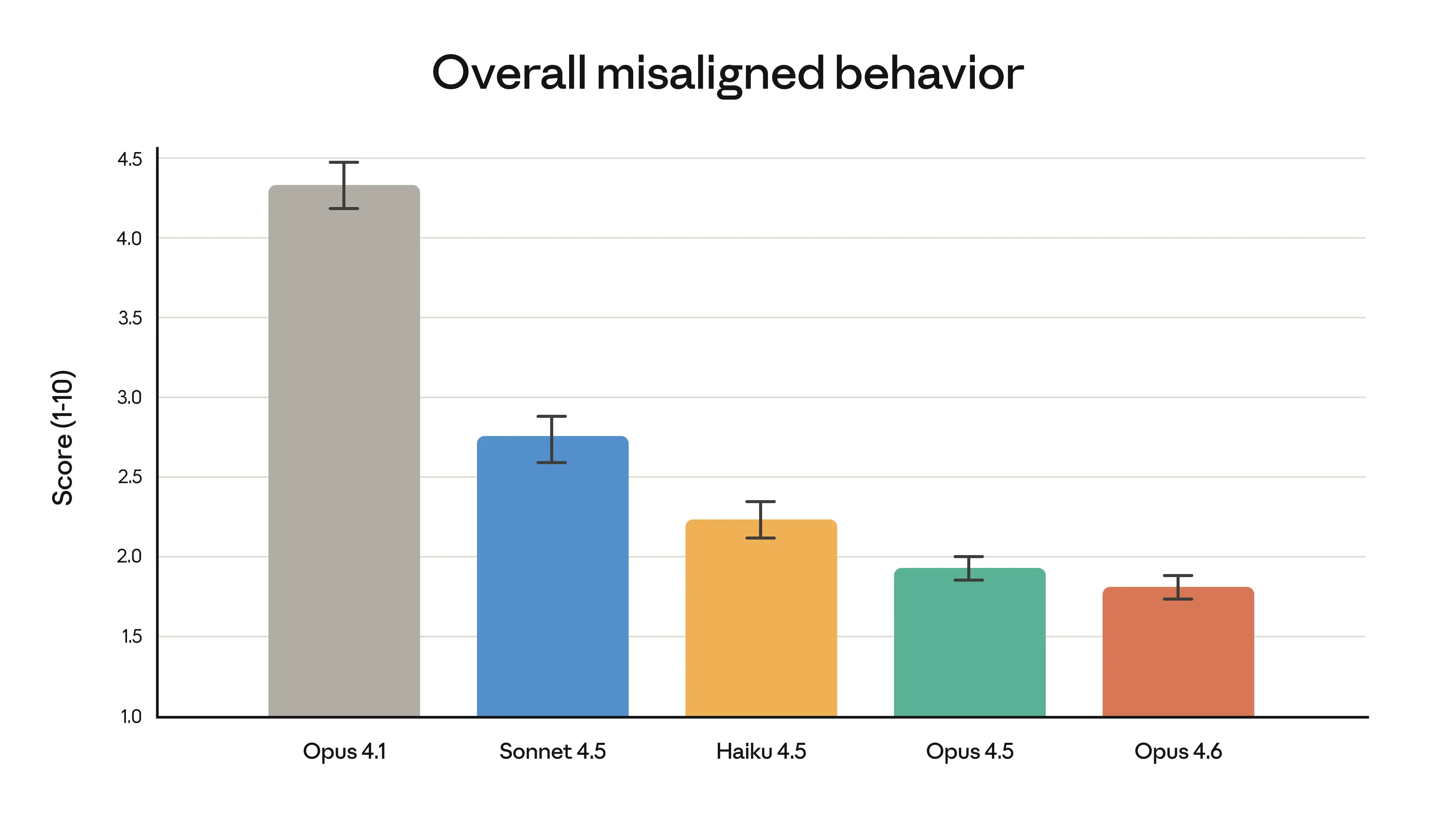
Claude Opus 4.6 implemented the most comprehensive safety assessment of any model, applying a wide variety of tests for the first time and upgrading several previously used tests, including new assessments of user safety, more sophisticated tests of the model's ability to reject potentially dangerous requests, and updated assessments of the model's ability to perform harmful actions stealthily. New methodologies, from interpretive science to the inner workings of AI models, were also tested to begin to understand why models behave in certain ways—and ultimately, to uncover issues that standard tests might miss.