Stop struggling with LM Studio's mock-up UI! Switch to Ollama!
LM Studio isn't the only easy-to-use local LLM application, and setting up Ollama can save you valuable hours.
Many people have been running local LLMs for quite some time now, and LM Studio is one of the best applications for enjoying the benefits of using local LLMs on your computer. It's polished, has a beautiful model browser, and downloading models from Hugging Face is almost effortless—until it malfunctions.
Model downloads can sometimes get stuck, and the frustrating process of manually removing a model, reconfiguring GPU layers, and reloading another model isn't pleasant. But LM Studio isn't the only easy-to-use local LLM application, and setting up Ollama can save you valuable hours.
The simplest way to run AI locally.
What is Ollama and why is it so popular?
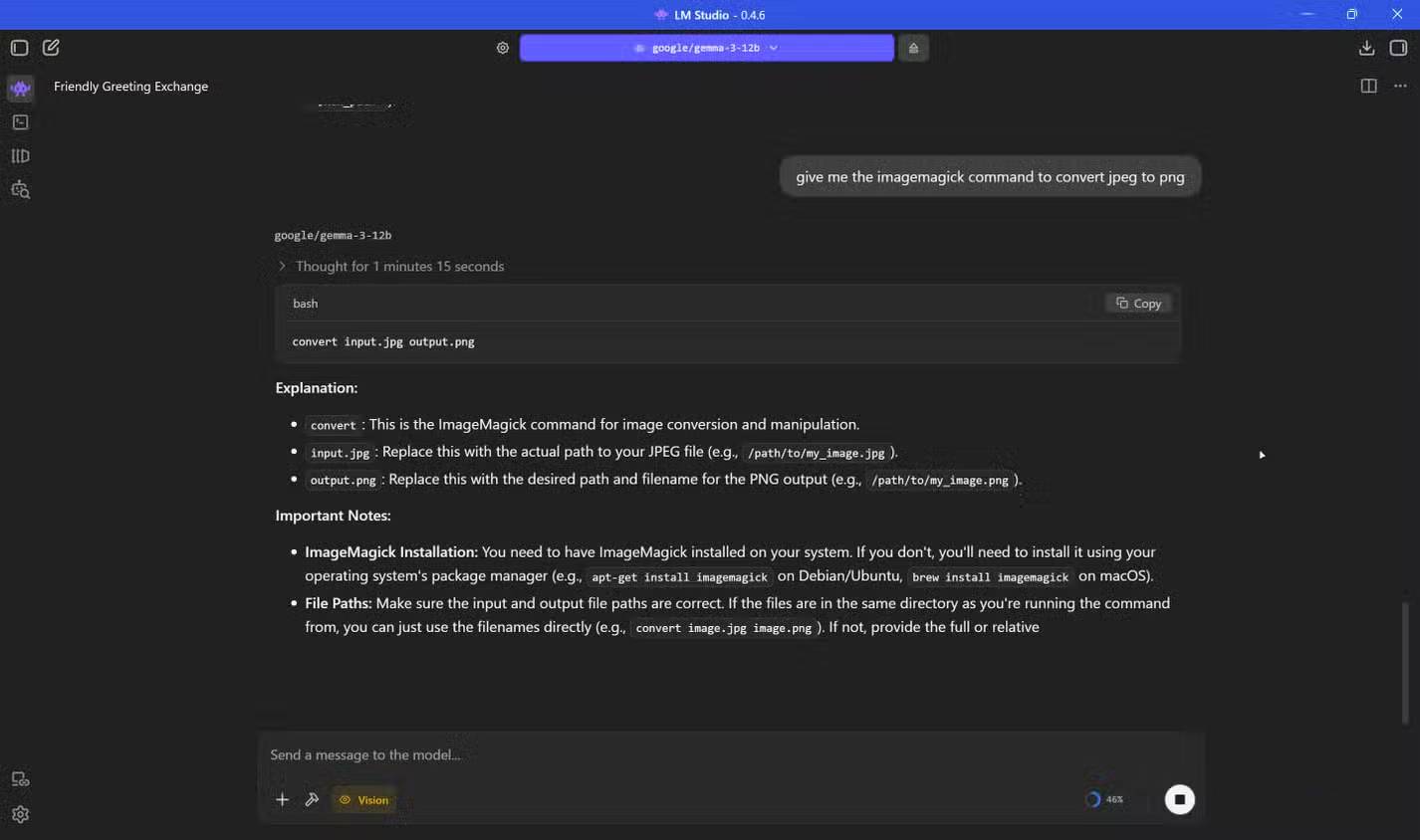
Ollama is a lightweight, open-source runtime for running local LLLM models. While LM Studio provides a full graphical user interface (GUI) with model browsing, chat tabs, and server controls, Ollama simplifies things into a clean command-line workflow and a local HTTP API. It runs a background server right out of the box, and everything else, from downloading models, switching between them, and querying them, happens via the terminal or through that API. There's also a minimalist UI if that's what you prefer.
If you've used Docker before, the model is almost identical. You download an image—or in this case, a model—and run it. The command `ollama pull [model name]` will download the model, `ollama run [model name]` will run it, and it will take you straight into an interactive chat. It might seem a bit restrictive, but the entire process from initial installation to chatting with a 7 billion model takes less than 5 minutes on a good connection.
A setup process that skips most of the usual complex steps.
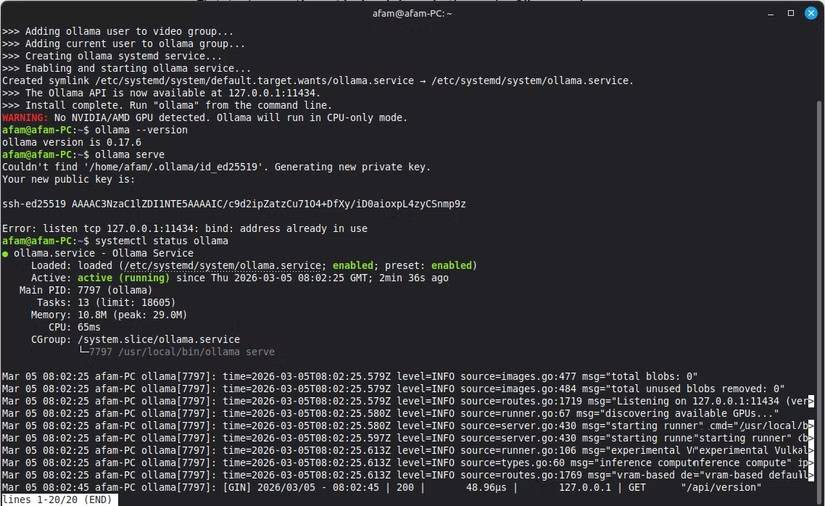
Installing Ollama only requires a curl command on Linux. On Windows, you can use the standard installer from the Ollama website. Once the installation is complete, Ollama will automatically launch a background service, and you're ready to download the models.
The model library on Ollama's website includes everything you'd expect: Llama 3, Mistral, Gemma 3, Phi-4, DeepSeek, Qwen, and a growing list of others. You can copy the run command directly from a model's page, paste it into your terminal, and Ollama will handle the download and launch in a single step. No need to browse through model browsers, no need for separate download queues, no need to wait for the application to register files to its internal catalog.
Switching models is equally easy. You don't need to perform manual uninstallation or adjust memory management sliders. You simply run a different model name, and Ollama handles the rest in the background.
The new API is the real standout feature.
Why did the developers build the entire workflow on Ollama?

The most important part is the API. Ollama provides a Chat Completions endpoint compatible with OpenAI at http://localhost:11434/v1. This means that any tools or scripts already built for the OpenAI API will work immediately with your local models. You just need to point the URL to localhost, set the API key to a dummy string (since it's not authenticated locally), and you're done.
This is crucial if you're building anything. There are several Python scripts that call the OpenAI API for testing. Switching to Ollama only takes about 30 seconds of tweaking as mentioned above. Just change the base URL and model name; no need to touch any other part of the code. In comparison, LM Studio has a local server mode with similar compatibility, but proper configuration adds more steps and quite a bit of UI navigation that Ollama doesn't require.
The switch is inexpensive and saves you hours you could easily spend struggling with LM Studio's loading behavior. For anyone primarily running models locally to power scripts, tools, or integrations—rather than chatting through a built-in graphical user interface—Ollama is the quick, lightweight, and less frustrating way to go. The command-line interface isn't intimidating at all once you realize the entire workflow is essentially encapsulated in just two commands. Everything else falls into place naturally from there.
- What is Ollama?
- Ollama (desktop application)
- The main difference between Ollama and LM Studio
- How to build and use Mock API in React app using Mirage.js
- How to Setup and Run Qwen 3 Locally with Ollama
- Using OpenClaw with Ollama: Building a local data analytics system.
- Alternative ways to run LLM locally instead of Ollama or llama.cpp
- How to generate mock test data using Go
- VS Code 1.122: A guide to using offline AI with Ollama and local modeling.
- 10 interesting secrets behind the logos of famous Hollywood studios
- TOP best tools for running LLM models on a computer
- Why should you stop using LM Studio and switch to the open-source alternative Jan?
- Offline AI vs. Online AI: Which is the best option right now?
- Top 5 AI models that write compact code and can run locally.
- Ollama (desktop application)
- 7 best AI software programs that can be installed on Windows
- The main difference between Ollama and LM Studio
- What is LM Studio? What are its applications?
- How to get started using LM Studio
- How to use LM Studio models in Claude Code
 Instructions on using Gemma 4 in VS Code
Instructions on using Gemma 4 in VS Code Ollama (desktop application)
Ollama (desktop application) The main difference between Ollama and LM Studio
The main difference between Ollama and LM Studio What is Ollama?
What is Ollama? How to run AI on a local Raspberry Pi with Ollama (LLM) and Open WebUI
How to run AI on a local Raspberry Pi with Ollama (LLM) and Open WebUI How to Setup and Run Qwen 3 Locally with Ollama
How to Setup and Run Qwen 3 Locally with Ollama