How to Setup and Run Qwen 3 Locally with Ollama
With support for over 100 languages and strong performance on reasoning, coding, and translation tasks, Qwen3 is comparable to many of today's leading models, including DeepSeek-R1, o3-mini, and Gemini 2.5..
Qwen3 is Alibaba's latest generation of large-scale language models. With support for over 100 languages and strong performance on reasoning, coding, and translation tasks, Qwen3 is comparable to many leading models today, including DeepSeek-R1, o3-mini , and Gemini 2.5 .
This guide will explain step by step how to run Qwen3 locally using Ollama. The guide will also build a lightweight local application using Qwen 3. This application will allow you to switch between Qwen3's reasoning modes and translate between different languages.
Why run Qwen3 locally?
Running Qwen3 locally offers several key benefits:
- Privacy : Data never leaves your machine.
- Latency : Faster local inference without round-trip APIs.
- Cost Savings : No token fees or cloud bills.
- Control : You can adjust prompts, choose patterns, and configure thinking modes.
- Offline Access : You can work without an Internet connection after downloading the model.
Qwen3 is optimized for both deep reasoning (thinking mode) and quick response (non-thinking mode) and supports over 100 languages.
Setup Qwen3 locally using Ollama
Ollama is a tool that allows you to run language models like Llama or Qwen locally on your computer using a simple command line interface.
Step 1: Install Ollama
Download Ollama for macOS, Windows or Linux from: https://ollama.com/download.
Follow the installation instructions and once installed, verify by running this command in terminal:
ollama --versionStep 2: Download and run Qwen3
Ollama offers multiple Qwen3 models designed to fit a wide range of hardware configurations, from lightweight laptops to high-end servers.
ollama run qwen3Running the above command will launch the default Qwen3 model in Ollama, which currently defaults to qwen3:8b. If you are working with limited resources or want faster startup times, you can explicitly run smaller variants like the 4B model:
ollama run qwen3:4bQwen3 is available in several variants, starting from the smallest 0.6b (523MB) parameter model to the largest 235b (142GB) parameter model. These smaller variants offer impressive performance for reasoning, compilation, and code generation, especially when used in think mode.
The MoE models (30b-a3b, 235b-a22b) are particularly interesting because they only activate a subset of experts for each inference step, allowing for large parameter counts while keeping runtime costs efficient.
In general, use the largest model your hardware can handle and drop back to 8B or 4B models for local responsive testing on consumer machines.
Here's a quick summary of all the Qwen3 models you can run:
|
Model |
Ollama Command |
Best suited for |
|
Qwen3-0.6B |
|
Lightweight tasks, mobile applications and edge devices |
|
Qwen3-1.7B |
|
Chatbots, assistants and low-latency applications |
|
Qwen3-4B |
|
General purpose tasks with balanced performance and resource usage |
|
Qwen3-8B |
|
Multilingual support and moderate reasoning ability |
|
Qwen3-14B |
|
Advanced reasoning, content creation and complex problem solving |
|
Qwen3-32B |
|
High-level tasks require strong reasoning and extensive context processing |
|
Qwen3-30B-A3B (MoE) |
|
Efficient performance with 3 operating parameters, suitable for encryption tasks |
|
Qwen3-235B-A22B (MoE) |
|
Large-scale applications, deep reasoning, and enterprise-grade solutions |
Step 3: Run Qwen3 in background (optional)
To serve the model via the API, run this command in Terminal:
ollama serveThis will make the model available for integration with other applications at http://localhost:11434.
Use Qwen3 locally
This section will walk you through a number of ways you can use Qwen3 locally, from basic CLI interaction to integrating models with Python.
Option 1: Run Inference via CLI
Once the model is downloaded, you can interact with Qwen3 directly in Terminal. Run the following command in Terminal:
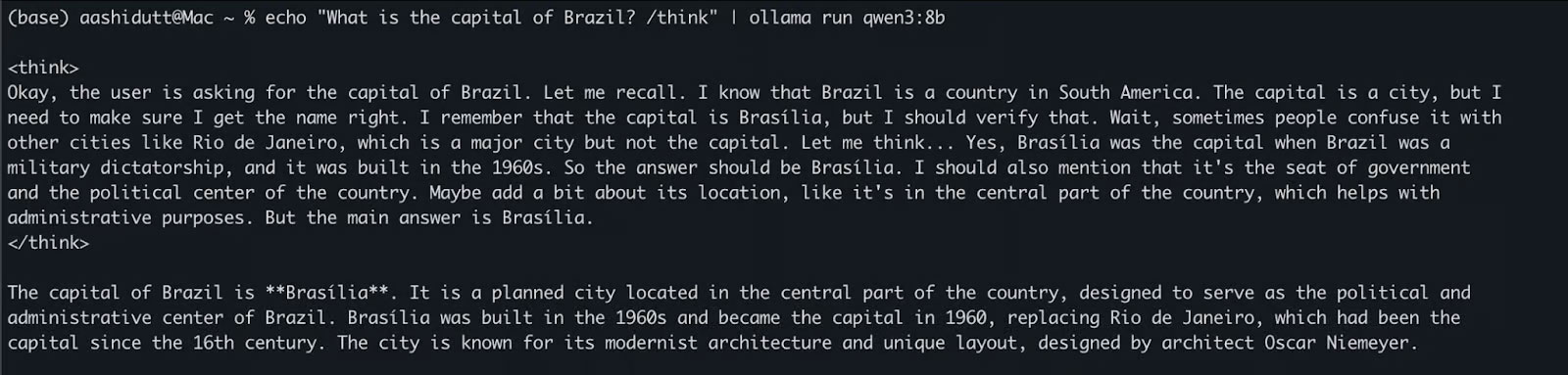
echo "What is the capital of Brazil? /think" | ollama run qwen3:8bThis is useful for quick or lightly interactive tests without writing any code. The /think tag at the end of the prompt instructs the model to engage in deeper, step-by-step reasoning. You can replace this with /no_think for a faster, shallower response, or skip it altogether to use the model's default inference mode.
Option 2: Access Qwen3 via API
While ollama serve is running in the background, you can interact with Qwen3 programmatically using the HTTP API, perfect for backend integration, automation, or REST client testing.
curl http://localhost:11434/api/chat -d '{ "model": "qwen3:8b", "messages": [{ "role": "user", "content": "Define entropy in physics. /think" }], "stream": false }'Here's how it works:
- curl makes a POST request (how we call the API) to the local Ollama server running at localhost:11434.
- Payload is a JSON object that has:
- "model": Specifies the model to use (here: qwen3:8b).
- "messages": List of chat messages containing roles and content.
- "stream": false: Ensures the response is returned all at once, not token by token.

Option 3: Access Qwen3 via Python
If you're working in a Python environment (like Jupyter, VSCode, or scripting), the easiest way to interact with Qwen3 is through the Ollama Python SDK. Start by installing ollama:
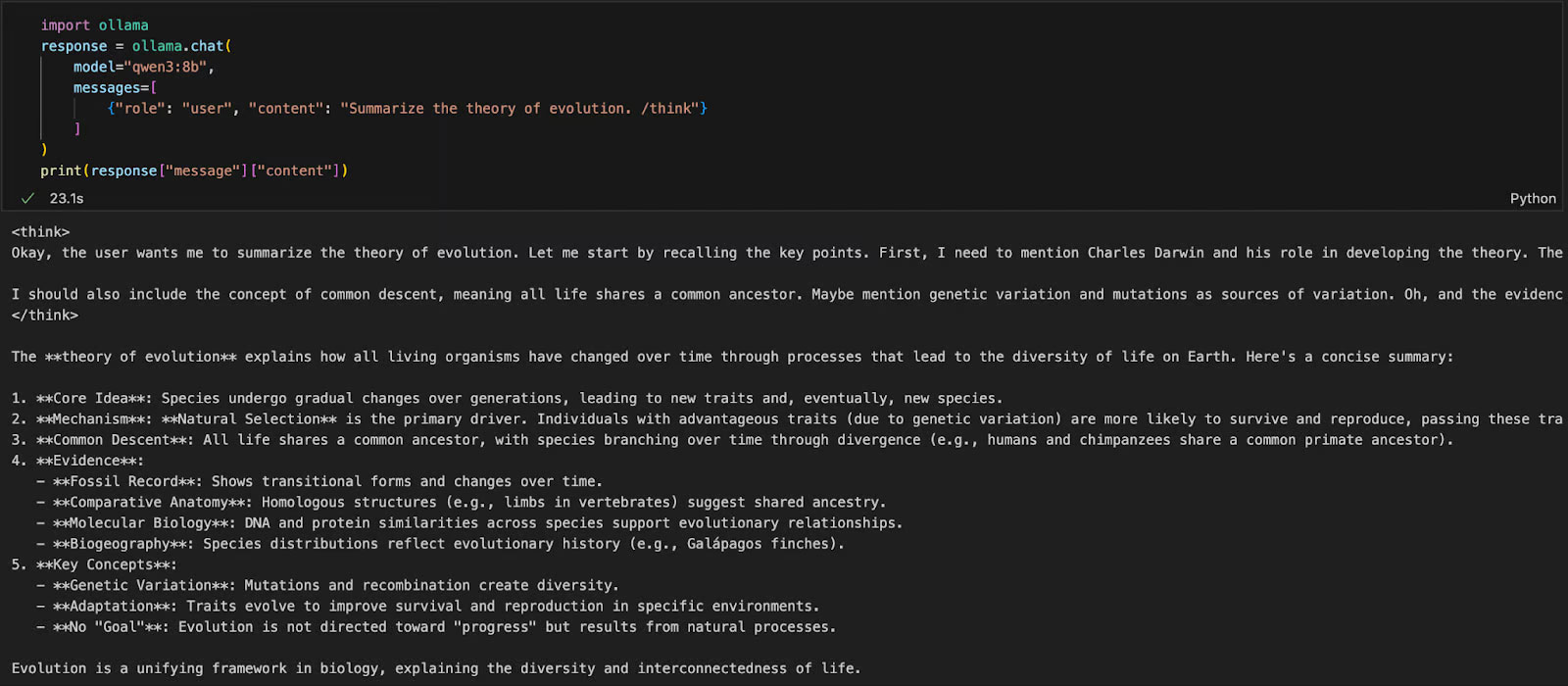
pip install ollamaThen run your Qwen3 model using this script (example is using qwen3:8b below):
import ollama response = ollama.chat( model="qwen3:8b", messages=[ {"role": "user", "content": "Summarize the theory of evolution. /think"} ] ) print(response["message"]["content"])In the code above:
- ollama.chat(.) sends a chat-style request to the local Ollama server.
- You specify the model (qwen3:8b) and the list of messages in a format similar to OpenAI's API.
- The /think tag asks for a step-by-step explanation model.
- Finally, the response is returned as a dictionary and you can access the model's answer using ["message"]["content"].
This approach is ideal for local testing, prototyping, or building LLM-powered applications without relying on cloud APIs.
Qwen3 brings advanced inference, fast decoding, and multi-language support to your local machine with Ollama.
With minimal setup you can:
- Run LLM inference locally without relying on the cloud
- Switch between quick and thoughtful responses
- Use API or Python to build smart apps