Multimodal AI: The evolution from intelligent machines to machines that can sense.
Multimodal AI—an AI technology that processes text, images, and audio simultaneously—is redefining the future of every industry..
In less than three years, from 2023 to 2026, AI has undergone a fundamental leap forward. From single-mode systems—processing only one type of data at a time—to multi-mode architectures capable of simultaneously integrating text, images, audio, and video. This shift is not simply a technical improvement; it is a philosophical change in how machines model and understand reality.
To give you a clearer picture, imagine you're standing in front of a doctor. He's not just reading your test results; he's also observing your facial expression, listening to how your voice trembles, reviewing X-rays, and comparing them to thousands of similar cases in his memory. All of this happens in seconds. That's exactly what Multimodal AI is learning to do, and it's doing it faster, more broadly, and with increasing accuracy than any human. This article will take you through the full picture of the technology that is reshaping the world.
1. What is Multimodal AI?
Before delving into the details, it's essential to understand a fundamental concept: modality in AI refers to the various types of input data that a system can process – including text, images, audio, video, sensors, biological data, and more.
Multimodal AI refers to artificial intelligence systems capable of processing and integrating information from various input data types—such as text, images, audio, and video—to produce more comprehensive and in-depth outputs. While traditional AI models often focus on a single method (such as text processing only or image recognition only), multimodal AI combines multiple data types to deliver more sophisticated and versatile interactions.
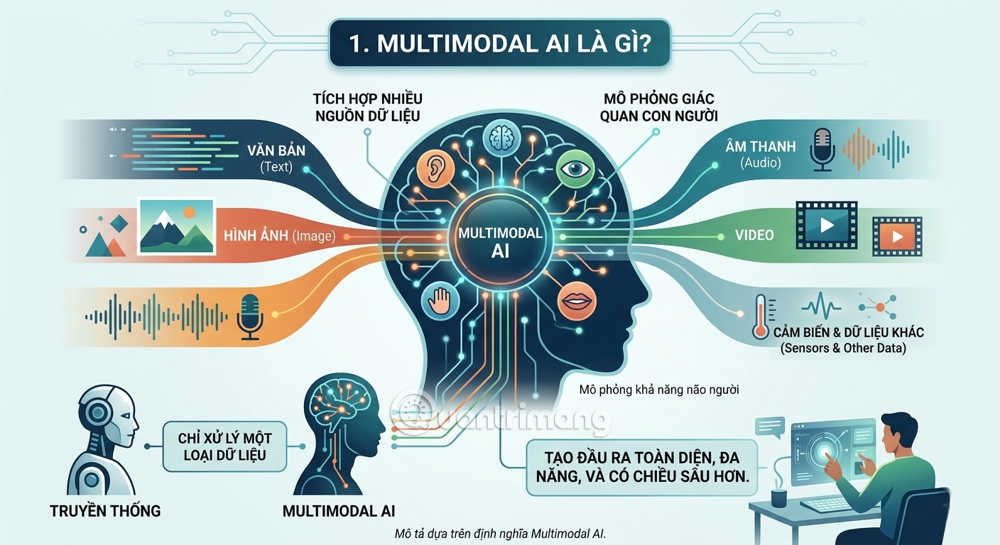
To put it more simply: if traditional AI is like an expert who only knows how to read books, then Multimodal AI is like a real human being – able to read, listen, see, feel, and process all of those things simultaneously to make a judgment.
The human brain is inherently a multimodal system, seamlessly integrating information from multiple senses to form an understanding of the world. Multimodal AI aims to mimic this capability, helping machines understand and respond more effectively to complex real-world situations.
2. History of formation and development context
Multimodal AI didn't emerge suddenly. It's the result of decades of parallel research in the fields of natural language processing (NLP), computer vision, and speech recognition.
The multimodal journey truly began strongly with the launch of GPT-4 in 2023 – the first model to efficiently handle both text and images. Following that, GPT-4o Vision took these interactions to a near-lifelike level.
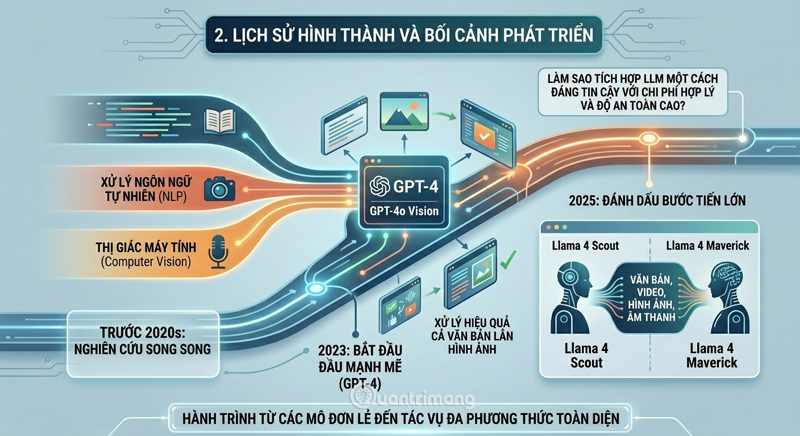
In the early 2020s, GPT-3 and GPT-4 facilitated natural dialogue, documentation summarization, and code writing. But by 2025, the question will no longer be "Which model is best?" but rather "How can we reliably integrate LLM at a reasonable cost and with high security?"
In October 2025, Meta Platforms launched two of its most advanced AI models to date: Llama 4 Scout and Llama 4 Maverick. Both are multimodal systems capable of processing and translating a wide range of data formats, including text, video, images, and audio – marking a major leap forward in AI's ability to interact with the world.
3. How Multimodal AI works
A typical Multimodal AI system consists of three main components:
Input Module: This is a collection of neural networks that process each type of data separately. For example, a CNN (Convolutional Neural Network) processes images, while a transformer processes text and an RNN processes audio sequences.
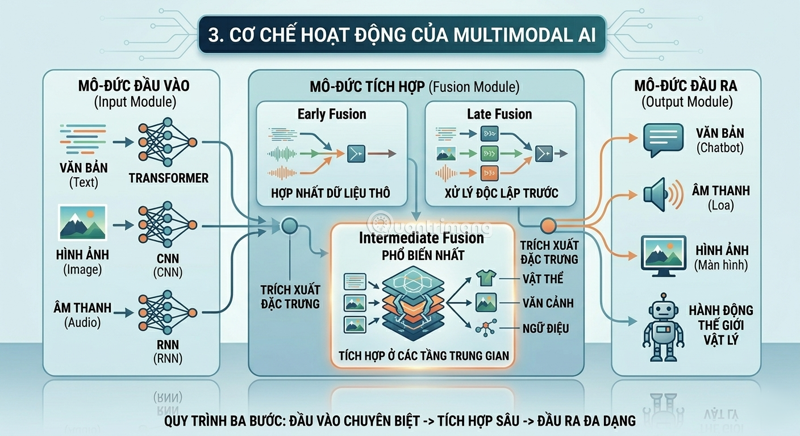
Fusion Module: This is the "heart" of the system – where different data streams are merged into a single representation. Good fusion helps AI understand the context by focusing on all available information. Feature extraction is a crucial step: with images, AI identifies objects and patterns; with text, it analyzes context, sentiment, and keywords.
Output Module: This module synthesizes everything to generate a response – which could be text, audio, images, or even actions in the physical world (with AI robots).
In terms of integration techniques, there are three main strategies:
- Early Fusion: Merge raw data from methods right from the start, before processing it separately.
- Late Fusion: Processes each method independently, then combines the results.
- Intermediate Fusion: Combining at intermediate layers – this is currently the most popular method, due to its ability to preserve the unique characteristics of each method, and is particularly effective when combining structured and unstructured data.
4. Leading Multimodal AI Models (2025–2026)
Leading models for 2025–2026 include GPT-4o/GPT-5, Claude 3 (Anthropic), Google Gemini 2.0, Gemma 3, Kosmos-2, and LLaMA 4.
GPT-4o (OpenAI): OpenAI's first truly multimodal grand language model, capable of processing and generating text, images, and audio naturally. It is designed for real-time contextual reasoning across a wide range of data formats.
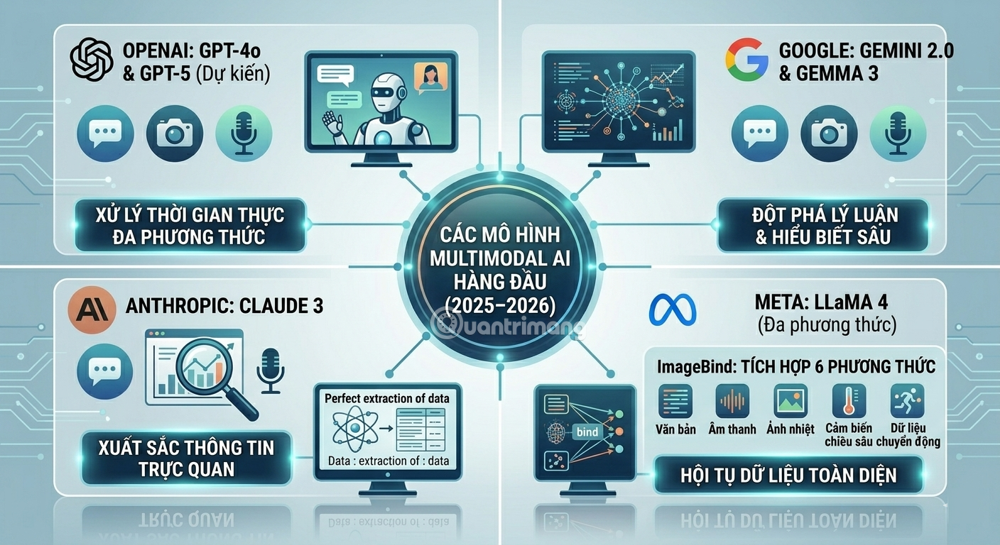
Gemini (Google): In 2025, Google will make significant strides in modeling capabilities with breakthroughs in reasoning, multimodal understanding, modeling efficiency, and innovation. Gemini 2.0 and Gemma 3 are key highlights of this year.
Claude 3 (Anthropic): Works with text and images, particularly excels at understanding visual information such as charts, diagrams, and photographs.
Meta ImageBind: While most current systems integrate three methods (text, image, audio), Meta's ImageBind has demonstrated the ability to integrate six methods: text, audio, image, thermal imaging, depth sensing, and motion data.
5. Role and practical applications
5.1 Healthcare – The sector undergoing the most significant transformation
Multimodal AI is reshaping the next-generation healthcare landscape by integrating diverse data sources – from medical imaging and electronic health records to wearable sensor data and genome sequencing. This convergence enables more accurate diagnoses, personalized treatment strategies, and real-time patient monitoring, ultimately shifting healthcare from reactive to predictive and preventative.
A specific example: a study combining chest X-ray images with audio data (breathing sounds and coughs) to diagnose COVID-19 showed an early detection rate of up to 98.91% when the two models were integrated.
By 2026, it is projected that 80% of initial medical diagnoses will involve AI analysis, up from 40% in 2024.
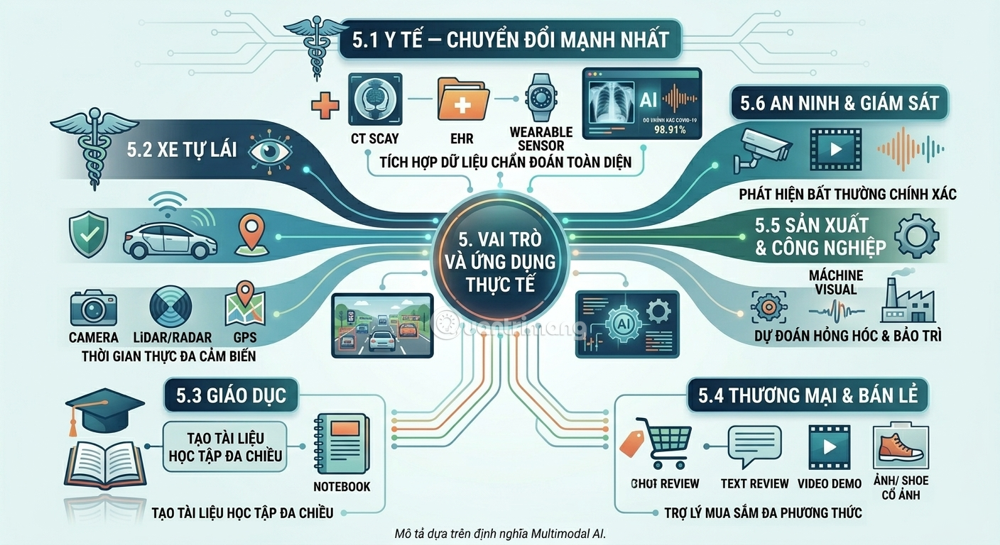
5.2 Self-driving cars and intelligent transportation
Self-driving cars are the most prominent application of Multimodal AI in the physical world. A vehicle needs to simultaneously process images from cameras, radar/LiDAR data, GPS signals, digital maps, and even communicate with other vehicles (V2V communication). Real-time data processing capabilities will become a standard feature in applications such as self-driving cars and smart environments.
5.3 Education
Large multimodal models can view a recorded lecture, extract key slides, and generate learning materials. This is changing how students interact with academic content – from one-way to multi-way, from passive to active.
5.4 E-commerce and Retail
Imagine a digital shopping assistant reading product descriptions, watching unboxing videos, and listening to influencer reviews. Using multimodal comprehension capabilities, it could answer questions like "Which running shoes have the best cushioning?" by synthesizing text reviews and video demos. If you send photos of your old shoes, it compares the worn pattern and suggests similar models.
5.5 Production and Industry
In manufacturing, Multimodal AI monitors equipment using image and sensor data. This helps predict when machinery might fail, enabling timely maintenance to keep production lines running smoothly.
5.6 Security and Surveillance
A surveillance system that uses both video and audio input can detect unusual activity far more accurately than one that relies on a single method.
6. Why is Multimodal AI important? – Its outstanding advantages
Higher accuracy and reliability
Research shows that humans only achieve 80%+ performance on auditory-visual reasoning tests – something that single-mode AI only achieves 40–50%. Modern multimodal models are approaching human performance levels on these benchmarks.
Gain a deeper understanding of the context.
When you send an AI an image along with a voice question, the system not only understands each individual component but also grasps the relationships between them – something that a single-mode AI cannot do.
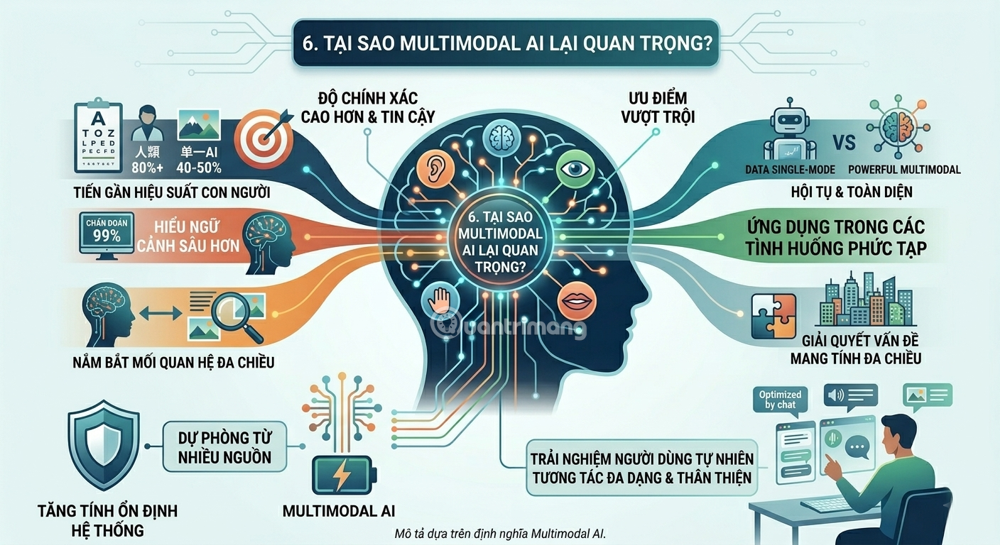
Increase system stability
Multimodal AI's ability to draw from multiple sources enhances system performance and reliability in information-constrained situations. This redundancy strengthens the overall reliability of the system.
A more natural user experience.
AI systems will become more interactive, allowing users to communicate with them through various means such as voice, text, and image messaging.
Applications in complex situations
Multimodal AI proves effective in complex situations involving both internal and external information, making it more suitable for practical applications where problems are multidimensional and intertwined.
7. Challenges and Disadvantages – A Realistic Perspective
No technology is perfect, and Multimodal AI is no exception. Here are some key hurdles to understand:
Enormous computational costs
Developing and maintaining multimodal AI systems can cost two to three times more than single-modal models due to infrastructure, talent, and integration requirements. These systems demand specialized infrastructure such as high-performance GPUs, large storage capacity, and low-latency networks.
In addition, multimodal models require 30–50% longer training time and significantly more hyperparameter tuning compared to single-modal architectures.
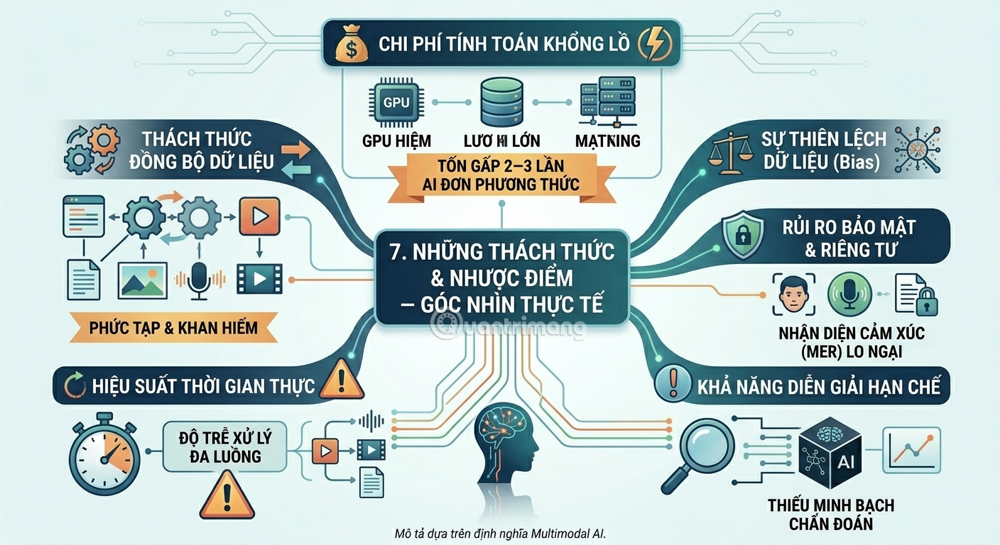
Data synchronization challenges
Integrating and synchronizing different data types is inherently complex, as each method has its own structure, format, and processing requirements – making effective combination difficult.
Training data is scarce and expensive.
High-quality labeled datasets that include multiple methods are rare, and collecting and annotating multimodal data is time-consuming and costly.
Real-time performance issues
One of the key operational limitations of Multimodal AI is the challenge of achieving real-time performance, particularly in time-sensitive applications such as self-driving cars, live monitoring, instant translation, or interactive virtual agents. Processing multiple simultaneous data streams – audio, video, and text – requires not only more computing resources but also highly synchronized pipelines to avoid latency or bottlenecks.
Limited interpretability
Explainability remains a key unresolved issue – ensuring that Multimodal AI models provide transparent and meaningful explanations for their predictions remains a major challenge, especially in highly accurate fields such as healthcare and law.
Security and privacy risks
With its ability to simultaneously process multiple types of personal data (faces, voice, private text), Multimodal AI raises serious questions about privacy. One particularly concerning application is multimodal emotion recognition (MER), which can identify and interpret human emotional states by combining text, speech, and facial expressions. The risk of misinterpreting emotions and manipulating users can affect individuals in many ways, including unfair treatment and human rights violations.
Data bias
Noisy multimodal data presents a major challenge: learning how to control or mitigate the impact of arbitrary noise in multimodal datasets remains an unresolved problem. Multimodal data tends to contain many complex forms of noise, making analysis and utilization significantly more difficult.
8. How to use Multimodal AI in practice
For both consumers and businesses, this is an effective approach to Multimodal AI:
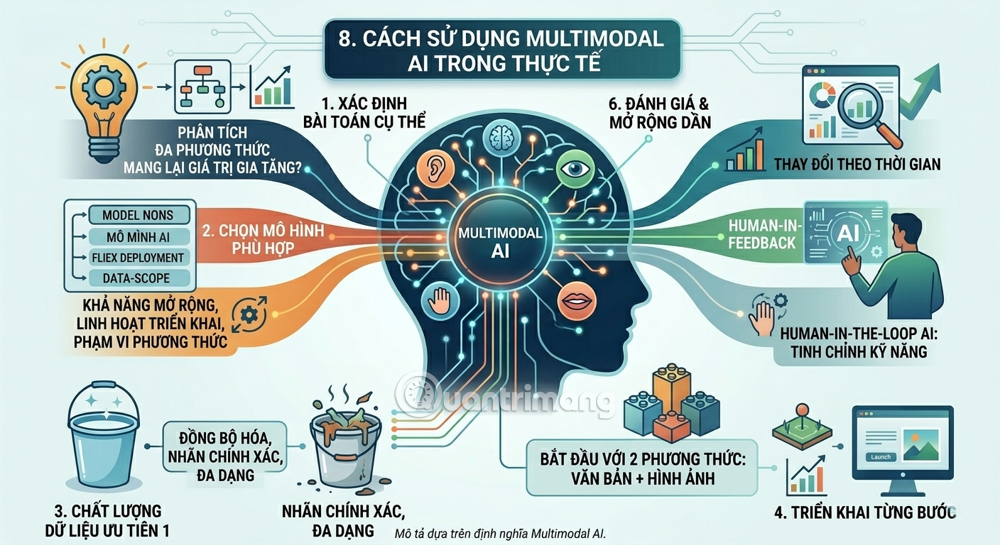
- Step 1 – Define the specific problem: Multimodal AI is not a solution to every problem. Clearly define: Does your data have more than one modal element? Does multimodal analysis truly add value?
- Step 2 – Choose the right model: When evaluating a platform for Multimodal AI development, businesses need to consider: scalability and deployment flexibility; data and AI governance; modal scope (support for text, images, video, audio, structured data); ecosystem and community; and scalability and integration capabilities.
- Step 3 – Data quality is the number one priority: Garbage in, garbage out – this principle is even more true for Multimodal AI. Training data needs to be synchronized, accurately labeled, and diverse.
- Step 4 – Deploy in stages: Instead of deploying everything at once, start with two methods (e.g., text + image), evaluate the results, and then gradually expand.
- Step 5 – Don't overlook the human element: It's crucial for the future to maintain "human-in-the-loop AI"—humans who can fine-tune and modify the system's skills—even as AI becomes increasingly automated.
9. Market and Trends in 2026
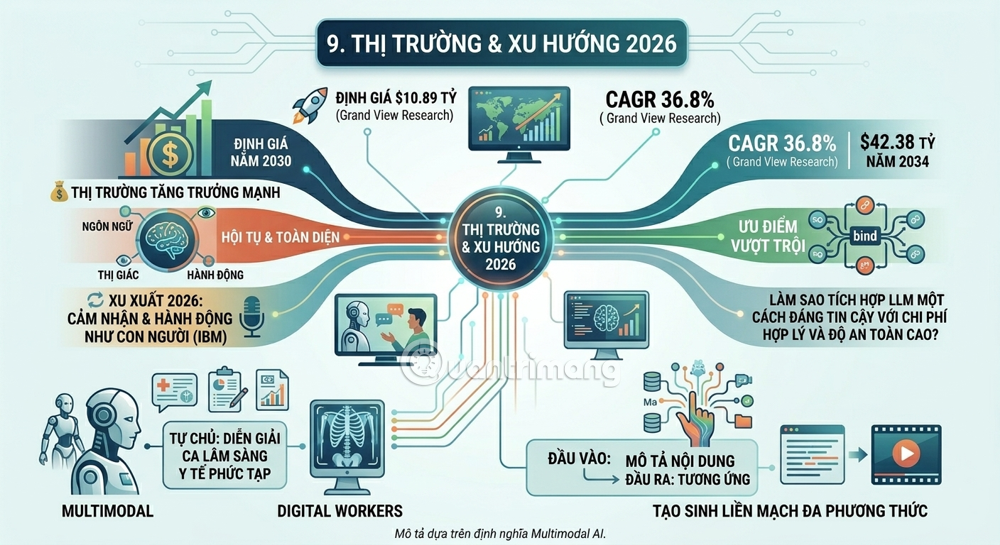
The global multimodal AI market is growing rapidly. According to Grand View Research, the market was valued at $1.73 billion in 2024 and is expected to reach $10.89 billion by 2030, with a CAGR of 36.8%. Some other sources estimate even more optimistic figures – the market reaching $2.51 billion in 2025 and potentially up to $42.38 billion by 2034.
According to experts from IBM, Multimodal AI is the most prominent trend in 2026: these models will be able to perceive and act in the world much more like humans, connecting language, vision, and actions. In the near future, we will begin to see multimodal "digital workers" who can autonomously complete various tasks, including interpreting complex medical clinical cases.
By 2026–2027, it is expected that seamless generation between methods will be possible – allowing users to describe content using any method and the system to generate corresponding output in other methods.
10. The Future: Where is Multimodal AI headed?
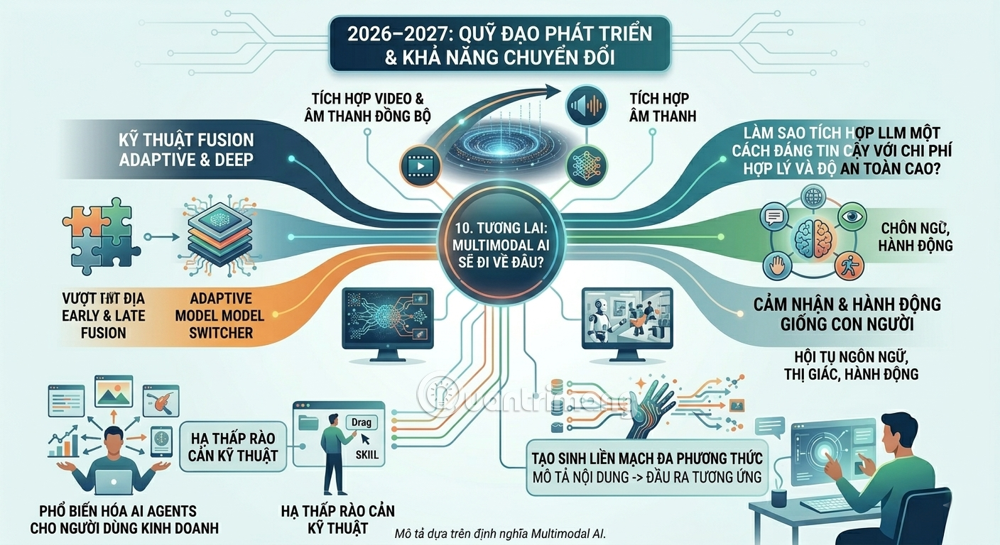
The trajectory of Multimodal AI development points toward several transformative capabilities that will emerge in 2026–2027 and beyond. Current systems primarily integrate text, images, and audio. Advanced systems are addressing video with synchronized audio – a significantly more complex argument.
Fusion techniques will continue to evolve beyond early and late fusion towards more adaptable hybrid and deep fusion methods. We expect more methods that allow for general multimodal learning with minimal supervision – making them more robust and applicable in real-world environments.
Particularly noteworthy is the popularization of AI: the ability to design and deploy AI agents is moving beyond the realm of developers and into the hands of everyday business users. By lowering technical barriers, organizations will witness a wave of innovation driven by those closest to real-world problems.
Conclude
Multimodal AI is not just a technical leap – it's a fundamental paradigm shift in how machines understand the world. From processing only one type of data, AI is learning to synthesize multiple streams of information simultaneously, much like the human brain does every day.
The winning organizations will be those that view Multimodal AI not as a technology checkbox, but as a core strategic capability requiring sustained investment in data, infrastructure, and expertise.
With a market projected to grow by nearly 37% annually, and strong investment from Google, OpenAI, Meta, Anthropic, and hundreds of emerging startups – multimodal AI is not a question of the future. The question is: are you ready to take advantage of it?