Convert XML into relational data used in DB2
In this next article we will show you another way to shred XML documents into relational tables..
 Convert XML into relational data
Convert XML into relational data
Shredding with annotated XML Schema
In this next article we will show you another way to shred XML documents into relational tables. This method is called annotation shredding or annotating schema because it is based on annotations in XML Schema. These annotations will define how XML elements and attributes in your XML data to map to columns in relational tables.
To perform annotated schema shredding, follow these steps:
- Identifying and creating relational target tables will keep the data shredded.
- Note your XML Schema to define mapping from XML to relational tables.
- Register XML Schema in the DB2 XML Schema Repository.
- Shredding XML documents with Command Line Processor commands or procedures.
Suppose you defined the relational tables that you want to shred, and then we'll look at annotating an XML Schema.
The annotation of XML Schema
Schema annotations, which are additional components and attributes in an XML Schema, provide mapping information. BD2 can use this information to shred XML documents into relational tables. Be aware that comments will not change the semantics of XML Schema. If a document is valid for an annotated schema, it is also valid for the original schema and vice versa. You can use annotated schema to validate XML documents like the original XML Schema.
Below is a line from an XML Schema:
The above line defines an XML element called street, and declares that its data is xs: string, which must appear at least once. You can add a comment to this component's definition to indicate that it will be shredded into the STREET column of the ADDRESS table. The annotation contains two additional attributes in the element definition:
db2-xdb: rowSet = "ADDRESS" db2-xdb: column = "STREET" />
Such annotations can also be provided for schema components instead of attributes, see below. You will see in Figure 8 why this is useful.
ADDRESS
STREET
The prefix xs is used for all structures belonging to the XML Schema language, the db2-xdb prefix is used for all DB2 schema annotations. These prefixes make it possible to clearly distinguish and ensure that the schema has a valid annotation with XML documents such as the original schema.
There are 14 different types of annotations. They allow you to specify what shredding, hashing, how to filter or transform shredding data and which order to insert into target tables. Table 4 gives you an overview of the available annotations, which are divided into logical groups according to the user's task. Individual comments will be described in more detail in Table 5.
If you want Use annotationSpecify target tables for hashing
db2-xdb: rowSet
db2-xdb: column
db2-xdb: SQLSchema
db2-xdb: defaultSQLSchema
Specify what to hash
db2-xdb: contentHandling
Convert data values while hashing
db2-xdb: expression
db2-xdb: normalization
db2-xdb: truncate
Filter the data
db2-xdb: condition
db2-xdb: locationPath
Map an element or attribute into multiple columns.
db2-xdb: rowSetMapping
Map some elements or attributes into the same column
db2-xdb: table
Define the order in the rows to be inserted into the target table, avoiding integrity breaks.
db2-xdb: rowSetOperationOrder
db2-xdb: order
Table 4. Overview and grouping of annotations of the schema
Note
Describe
db2-xdb: defaultSQLSchema
Default relational schema for target tables
db2-xdb: SQLSchema
Override the default schema for individual tables.
db2-xdb: rowSet
The table name to which the element or attribute is mapped
db2-xdb: column
Column name and element or attribute mapped
db2-xdb: contentHandling
With an XML component, this annotation defines how to get the value inserted into the target column.
db2-xdb: truncate
Specify whether the value will be cut if its length is greater than the length of the target column.
db2-xdb: normalization
Indicates how to handle white space - valid values are whitespaceStrip, canonical, and original
db2-xdb: expression
Specifying the expression will be applied to the data before inserting into the target table.
db2-xdb: locationPath
Filters based on XML content. For example, will be shredded into cust table if it is a customer address; It will also be shredded into the employee table if it is an employee address.
db2-xdb: condition
Specifies the condition of the value so that the data is inserted into the target table only when all conditions are satisfied.
db2-xdb: rowSetMapping
Allows users to specify multiple maps, for the same or different tables, for an element or attribute.
db2-xdb: table
Map multiple elements or attributes into one column
db2-xdb: order
Specify the insert order of rows between multiple tables
db2-xdb: rowSetOperationOrder
Group multiple db2-xdb: order annotations together.
To demonstrate the annotated schema separation process, let's use the shredding script in Figure 1 as an example. Suppose that the target tables are all defined as shown in Figure 1. Annotation schema defines the desired mapping as provided in Figure 8. Observe the lines highlighted. The first bold line declares the db2-xdb name prefix, which is used throughout the schema to distinguish BD2 annotations with regular XML Schema tabs. The first case using this prefix is in the comment db2-xdb: defaultSQLSchema, this is the comment defining the relational schema of the target tables. The next comment appears in the definition of the name element. Two properties of this annotation db2-xdb: rowSet = "ADDRESS" and db2-xdb: column = "NAME" define the table and target column for the name element. Similarly, street and city components are also mapped to the corresponding columns of the ADDRESS table. The next two annotations map the phone number and the type attribute to the columns in the PHONES table. The last block of comments belongs to the Cid attribute definition. Because the Cid attribute becomes the join key between the ADDRESS and PHONE tables, it must be mapped to both tables. Two rows of mapping are required, requiring the use of annotation elements instead of annotation attributes . First db2-xdb: rowSetMapping will map the Cid attribute to the CID column in the ADDRESS table. Then db2-xdb: rowSetMapping will assign the Cid attribute to the CID column in the PHONES table.
elementFormDefault = "qualified"
xmlns: db2-xdb = "http://www.ibm.com/xmlns/prod/db2/xdb1">
db2admin
db2-xdb: rowSet = "ADDRESS" db2-xdb: column = "NAME" />
maxOccurs = "unbounded">
minOccurs = "1" db2-xdb: rowSet = "ADDRESS"
db2-xdb: column = "STREET" />
minOccurs = "1" db2-xdb: rowSet = "ADDRESS"
db2-xdb: column = "CITY" / >
minOccurs = "1" />
minOccurs = "1" />
maxOccurs = "unbounded" db2-xdb: rowSet = "PHONES"
db2-xdb: column = "PHONENUM">
type = "xs: string" db2-xdb: rowSet = "PHONES"
db2-xdb: column = "PHONETYPE" />
ADDRESS
CID
PHONES
CID
Define intuitive schema annotations in IBM Data Studio
You can manually add annotations to an XML Schema, using any text editor or XML Schema editor. Alternatively, you can use the Annotated XSD Mapping Editor in IBM Data Studio Developer. To invoke the editor, right-click the name of an XML Schema and select Open With, Annotated XSD Mapping Editor. The map editor window will then be displayed as shown in Figure 9. The left side of the editor shows the hierarchical document structure defined by XML Schema (Source). The right side shows the tables and columns of the relational target schema (Target). You can add map relationships by connecting source items to the target column. Besides, the program also has a discovery function to help you find possible relationships. Mapped relationships will be presented in the editor using lines between the source and target columns.
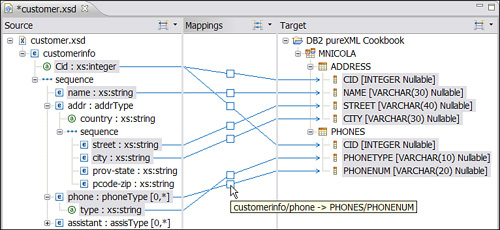
Figure 9: Annotated XSD Mapping Editor in Data Studio Developer
Register annotated schema
After you have created an annotated XML Schema, you need to register it in the XML Schema Repository of the database. For the schema annotated in Figure 8, we have full authority to issue its REGISTER XMLSCHEMA command with its COMPLETE and ENABLE DECOMPOSITION options as shown in Figure 10. In this example, XML Schema is assumed to be populated. Reside in the file /xml/myschemas/cust2.xsd. Thanks to the registration action, it is assigned the SQL Id db2admin.cust2xsd. This id can be used for reference later. The COMPLETE option of the command indicates that there are no additional XML Schema documents added. The ENABLE DECOMPOSITION option indicates that XML Schema can be used not only for document validation but also for shredding ( shred ).
REGISTER XMLSCHEMA 'http://pureXMLcookbook.org'
FROM '/xml/myschemas/cust2.xsd'
AS db2admin.cust2xsd COMPLETE ENABLE DECOMPOSITION;
Figure 11 shows that you can query the DB2 item view syscat.xsrobjects to determine whether the registered schema is enabled for separation (Y) or not (N).
SELECT SUBSTR (objectname, 1.10) AS objectname,
status, decomposition
FROM syscat.xsrobjects;
OBJECTNAME STATUS DECOMPOSITION
---------- ------ -------------
CUST2XSD C Y
The DECOMPOSITION status of the annotated schema is automatically changed to X ( inoperative ) and shredding is disabled, if any target tables are dropped or a target column is changed. No warnings will appear when this happens and future attempts to use the schema for shredding will fail. You can use the following commands to disable and enable an annotation schema for shredding:
ALTER XSROBJECT cust2xsd DISABLE DECOMPOSITION;
ALTER XSROBJECT cust2xsd ENABLE DECOMPOSITION;
Separate an XML document at a time
After registering and activating an annotated XML Schema, you can parse XML documents with the DECOMPOSE XML DOCUMENT command or with the stored procedure. The DECOMPOSE command XML DOCUMENT is very convenient to use in the DB2 Command Line Processor (CLP), and the stored procedure can be called from a certain program or CLP. The CLP command will need two input parameters: the filename of the shredded XML document and the SQL Id of the annotated schema, as shown in the example below:
DECOMPOSE XML DOCUMENT /xml/mydocuments/cust01.xml
XMLSCHEMA db2admin.cust2xsd VALIDATE;
The VALIDATE keyword is completely optional and indicates whether XML documents are validated against the schema as part of the shredding process. While shredding, DB2 looks at both the XML document and the annotated schema, detecting basic schema schema violations even if the VALIDATE keyword is not specified. For example, the shredding process will fail if a mandatory component is lost, even if the component is not shredded and the VALIDATE keyword is ignored. Similarly, components that are not related to the problem in question or violations of data types also cause failure for the splitting process. The reason here is that the shredding process will go through the entire annotated and documented XML Schema and detect schema violations even if the XML parser does not perform validation. .
To separate XML documents from an application program, you can use the XDBDECOMPXML stored procedure. The parameters of this procedure are shown in Figure 12 and are described in detail in Table 6.
>> - XDBDECOMPXML - (- rschema -, - xmlschemaname -, - xmldoc -, ---->
> - documentid -, - validation -, - reserved -, - reserved -, ------>
> - reserved -) ------------------------------------------- -----> <
Figure 12: Syntax and parameters of stored procedure XDBDECOMPXML
Parameters
Describe
rschema
The relational schema part of the SQL Id (SQL identifier) is two parts in the annotated XML Schema. For example, the SQL Id of the SQL Schema is db2admin.cust2xsd, then you should pass the string 'db2admin' to this parameter. In DB2 for z / OS, this value must be 'SYSXSR' or NULL.
xmlschemaname
The second part is in the annotated SQL Id of the XML Schema. If the XML Schema ID is db2admin.cust2xsd, you can pass the string 'cust2xsd' to this parameter. The value at this time cannot be NULL.
xmldoc
In DB2 for Linux, UNIX, and Windows, this parameter is of type BLOB (1M) and will separate the XML document. In DB2 for z / OS, this parameter is of type CLOB AS LOCATOR. And cannot be NULL.
documentid
A string that the caller can use to distinguish the input XML document. The value provided will be replaced for any purpose of $ DECOMP_DOCUMENTID specified in the db2-xdb: expression or db2-xdb: condition annotations.
validation
Values can be received as 0 (invalid) and 1 (validity is made). This parameter does not exist in DB2 for z / OS.
reserved
Parameters are reserved for later use. The values passed for these arguments must be NULL. These parameters do not exist in DB2 for z / OS.
A Java code used to call the stored procedure is shown in Figure 13.
CallableStatement callStmt = child.prepareCall (
"call SYSPROC.XDBDECOMPXML (?,?,?,?,?, null, null, null)");
File xmldoc = new File ("c: mydoc.xml");
FileInputStream xmldocis = new FileInputStream (xmldoc);
callStmt.setString (1, "db2admin");
callStmt.setString (2, "cust2xsd");
// document to be shredded:
callStmt.setBinaryStream (3, xmldocis, (int) xmldoc.length ());
callStmt.setString (4, "mydocument26580");
// no validation schema in this call:
callStmt.setInt (5, 0);
callStmt.execute ();
The input parameter for XML documents is CLOB AS LOCATOR in DB2 for z / OS, and it will be BLOB (1M) type in DB2 for Linux, UNIX, and Windows. If you expect your XML documents to be larger than 1MB, use one of the procedures listed in Table 7. These procedures are the same except for their names and the size of the xmldoc input parameters. . When you call a procedure, DB2 will specify the memory according to the declared size of the input parameters. For example, if all of your input documents are almost 10MB in size, the procedure XDBDECOMPXML10MB will be the best option for memory.
Document Size Procedures Supported fromXDBDECOMPXML
≤1MB
DB2 9.1
XDBDECOMPXML10MB
≤10MB
DB2 9.1
XDBDECOMPXML25MB
≤25MB
DB2 9.1
XDBDECOMPXML50MB
≤50MB
DB2 9.1
XDBDECOMPXML75MB
≤75MB
DB2 9.1
XDBDECOMPXML100MB
≤100MB
DB2 9.1
XDBDECOMPXML500MB
≤500MB
DB2 9.5 FP3
XDBDECOMPXML1GB
≤1GB
DB2 9.5 FP3
XDBDECOMPXML1_5GB
≤1.5GB
DB2 9.7
XDBDECOMPXML2GB
≤2GB
DB2 9.7
For platform compatibility, DB2 for z / OS supports the procedure XDBDECOMPXML100MB with parameters like DB2 for Linux, UNIX, and Windows, including parameters for validation.
Separate XML documents in size
DB2 9.7 for Linux, UNIX, and Windows introduced a new procedure called XDB_DECOMP_XML_FROM_QUERY. It uses an annotated schema to separate one or more selected XML documents from columns of type XML, BLOB, or VARCHAR FOR BIT DATA. The main difference to the procedure XDBDECOMPXML is XDB_DECOMP_XML_FROM_QUERY using an SQL query as a parameter and executing it to obtain input documents from the DB2 table. With a larger number of documents, the LOAD operation followed by " bulk decomp " can be more efficient than shredding documents. Figure 14 shows the parameters of this procedure. The parameters commit_count and allow_access are similar to the corresponding parameters of the DB2 IMPORT utility. The parameters total_docs, num_docs_decomposed, and result_report are output parameters that provide information about the results of a large shredding process. All parameters are explained in Table 8.
>> - XDB_DECOMP_XML_FROM_QUERY - (- rschema -, - xmlschema -, ->
> - query -, - validation -, - commit_count -, - allow_access -, ---->
> - reserved -, - reserved2 -, - continue_on_error -, -------------->
> - total_docs -, - num_docs_decomposed -, - result_report -) -> <
Figure 14: Procedure XDB_DECOMP_XML_FROM_QUERY
Parameters
Describe
rschema
Similar to XDBDECOMPXML
xmlschema
Similar to xmlschemaname for XDBDECOMPXML
query
Query string of type CLOB (1GB), does not receive NULL value. The query must be an SQL or SQL / XML SELECT statement and must return two columns. The first column must contain a document Id other than the XML document in the second column of the result set. The second column contains shredded XML documents and must be of type XML, BLOB, VARCHAR FOR BIT DATA, or LONG VARCHAR FOR BIT DATA.validation
Values can be: 0 (invalid) and 1 (validity is made).
commit_count
Integer value equal to or greater than 0 . Value 0 means the procedure does not make any commitments. The value n means that a commit will be executed after n document separations are successful.
allow_access
Receive a value of 1 or 0. If the value is 0, the procedure will obtain a reserved key on all tables referenced in the annotated XML Schema. If the value is 1, the procedure will get a shared key.
reserved,
reserved2
Parameters are reserved for future use and must be NULL.
continue_on
_error
May be 1 or 0 . Value 0 means the procedure will stop because the first document cannot be parsed; for example, if the document does not match the XML Schema.
total_docs
An output parameter indicates the total number of documents that the procedure tries to separate.
num_docs_
decomposed
The output parameter indicates the number of documents that have been successfully decomposed.
result_report
Output parameter of type BLOB (2GB). Contains an XML document to provide diagnostic information for documents that have not been successfully decomposed. This report will not be generated if all documents have been successfully shredded.
Figure 15 shows a procedure call XDB_DECOMP_XML_FROM_QUERY in CLP. This procedure call will read all XML documents from the info column of customer table and shred them with annotated XML Schema db2admin.cust2xsd. The procedure commits to a 25-document cycle and does not stop if a certain document cannot be shredded.
call SYSPROC.XDB_DECOMP_XML_FROM_QUERY
('DB2ADMIN', 'CUST2XSD', 'SELECT cid, info FROM customer',
0, 25, 1, NULL, NULL, '1',?,?,?);
Value of output parameters
--------------------------
Parameter Name: TOTALDOCS
Parameter Value: 100
Parameter Name: NUMDOCSDECOMPOSED
Parameter Value: 100
Parameter Name: RESULTREPORT
Parameter Value: x ''
Return Status = 0
If you often perform large volume shredding in the CLP, use the command DECOMPOSE XML DOCUMENTS instead of the procedure. This method will be more convenient in the case of command line operations and still perform tools like the procedure XDB_DECOMP_XML_FROM_QUERY. Figure 16 shows the syntax of the command. Different clauses and keywords of the command have the same meaning as the corresponding procedure parameters. For example, the query is a SELECT statement that provides input documents, and xml-schema-name is a two-part SQL Id of the annotated XML Schema.
>> - DECOMPOSE XML DOCUMENTS IN ---- ' query ' ---- XMLSCHEMA ------->
.-ALLOW NO ACCESS-.
> --xml-schema-name-- + ---------- + - + ----------------- + ------- ---->
'-VALIDATE-' '-ALLOW ACCESS ----'
> - + ---------------------- + - + ------------------- + -------------->
'-COMMITCOUNT --integer- ' '-CONTINUE_ON_ERROR-'
> - + -------------------------- + ------------------- -------------> <
'-MESSAGES --message-file-
Figure 17 illustrates the execution of the DECOMPOSE XML DOCUMENTS command in the DB2 Command Line Processor.
DECOMPOSE XML DOCUMENTS IN 'SELECT cid, info FROM customer'
XMLSCHEMA db2admin.cust2xsd MESSAGES decomp_errors.xml;
DB216001I The DECOMPOSE XML DOCUMENTS command successfully
decomposed all "100" documents.
If you do not specify a message-file , an error report will appear at the output. Figure 18 shows an error report. With the document failing in the shredding process, an error message will display the document Id (xdb: documentId). This id is retrieved from the first column generated by the SQL statement in the DECOMPOSE XML DOCUMENTS command. The error report also contains DB2 error messages for failed documents. Figure 18 shows that the 1002 document contains an unexpected XML attribute called status, and the 1005 document contains an invalid abc attribute or value because XML Schema expects to find an xs value. : integer.
xmlns: xdb = "http://www.ibm.com/xmlns/prod/db2/xdb1">
1002
SQL16271N Unknown attribute "status" at or
near line "1" in document "1002".
1005
SQL16267N An value XML "abc" at or near
dòng "1" trong document "1005" is not valid according to
its declared XML schema type "xs: integer" or is outside
phạm vi hỗ trợ của giá trị cho kiểu schema XML
Conclude
When you want to make shredding XML documents into relational tables, remember that XML and relational data are based on different platform data models. The 1-n relationship is interpreted using multiple tables and joins the relationships between them. In contrast, XML documents tend to have stacking and hierarchical structures that can represent multiple 1-n relationships in a document. XML allows components to be repeated at any number of times and XML Schemas can define hundreds, even thousands, of optional components and attributes that can exist or not exist in any asset. given. Due to this difference, shredding XML data into relational tables can be difficult, inefficient, and sometimes quite complex.
If the architecture of XML data is within the limits of the complexity allowed for mapping into relational tables, in addition, if your XML format cannot be changed over time, double XML shredding when possible, is a useful way to provide existing relational applications and reporting software.
DB2 provides two methods for shredding data. The first method uses SQL INSERT statements with the XMLTABLE function. Such an INSERT statement is required for each target table and many statements can be combined in a stored procedure to avoid repeating the analysis of the same XML documents. Shredding statements can include XQuery and SQL functions, join other tables, or references to DB2 strings. These features allow for highly customizable and flexible hashing, but require manual coding. The second method for hashing XML data is to use annotations in an XML Schema to define mapping from XML to database tables and columns. IBM Data Studio Developer provides an intuitive interface that makes it convenient and does not require manual code for this mapping process.