Table of Contents
This updated guide examines Name: How to Delete Duplicate Records in Oracle and organizes the essential facts, background, and practical takeaways in clear American English.
Method 1
Identifying your Duplicate
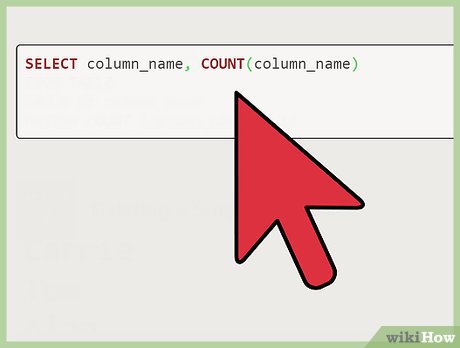 Identify the duplicate. In this case, identify the example duplicate, "Alan." Make sure that the records you are trying to delete are actually duplicates by entering the SQL below.
Identify the duplicate. In this case, identify the example duplicate, "Alan." Make sure that the records you are trying to delete are actually duplicates by entering the SQL below.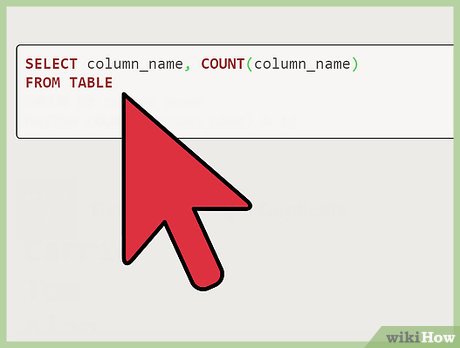 Identifying from a column named "Names. " In the instance of a column named "Names," you would replace "column_name" with Names.
Identifying from a column named "Names. " In the instance of a column named "Names," you would replace "column_name" with Names. Identifying from other columns. If you were trying to identify the duplicate by a different column, for example the age of Alan rather than his name, you would enter "Ages" in the place of "column_name" and so on.
Identifying from other columns. If you were trying to identify the duplicate by a different column, for example the age of Alan rather than his name, you would enter "Ages" in the place of "column_name" and so on.
selectcolumn_name,count(column_name)fromtablegroupbycolumn_namehavingcount(column_name)>1;
Method 2
Deleting a Single Duplicate
 Select "name from names. " After "SQL," which stands for Standard Query Language, enter "select name from names."
Select "name from names. " After "SQL," which stands for Standard Query Language, enter "select name from names." Delete all of the rows with the duplicate name. After "SQL," enter "delete from names where name='Alan';." Note that capitalization is important here, so this will delete all of the rows named "Alan." After "SQL," enter "commit."[1]
Delete all of the rows with the duplicate name. After "SQL," enter "delete from names where name='Alan';." Note that capitalization is important here, so this will delete all of the rows named "Alan." After "SQL," enter "commit."[1] Renter the row without a duplicate. Now that you have deleted all rows with the example name "Alan," you can insert one back by entering "insert into name values ('Alan');." After "SQL," enter "commit" to create your new row.
Renter the row without a duplicate. Now that you have deleted all rows with the example name "Alan," you can insert one back by entering "insert into name values ('Alan');." After "SQL," enter "commit" to create your new row.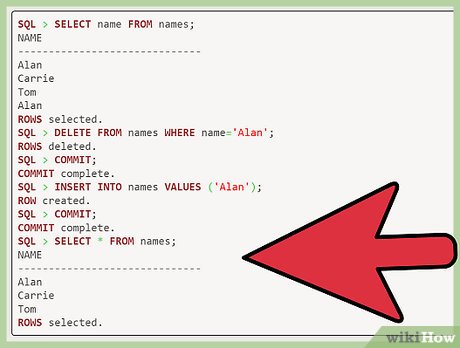 See your new list. Once you have completed the above steps, you can check to make sure you no longer have duplicate records by entering "select * from names."
See your new list. Once you have completed the above steps, you can check to make sure you no longer have duplicate records by entering "select * from names."
SQL>selectnamefromnames;NAME------------------------------AlanCarrieTomAlanrowsselected.SQL>deletefromnameswherename='Alan';rowsdeleted.SQL>commit;Commitcomplete.SQL>insertintonamesvalues('Alan');rowcreated.SQL>commit;Commitcomplete.SQL>select*fromnames;NAME------------------------------AlanCarrieTomrowsselected.
Method 3
Deleting Multiple Duplicates
 Select the RowID you want to delete. After "SQL," enter "select rowid, name from names;."
Select the RowID you want to delete. After "SQL," enter "select rowid, name from names;." Delete the duplicate. After "SQL," enter "delete from names a where rowid > (select min(rowid) from names b where b.name=a.name);" to delete duplicate records.[2]
Delete the duplicate. After "SQL," enter "delete from names a where rowid > (select min(rowid) from names b where b.name=a.name);" to delete duplicate records.[2] Check for duplicates. After you have completed the above, commands check to see if you still have duplicate records by entering "select rowid,name from names;" and then "commit."
Check for duplicates. After you have completed the above, commands check to see if you still have duplicate records by entering "select rowid,name from names;" and then "commit."
SQL>selectrowid,namefromnames;ROWIDNAME------------------ ------------------------------AABJnsAAGAAAdfOAAAAlanAABJnsAAGAAAdfOAABAlanAABJnsAAGAAAdfOAACCarrieAABJnsAAGAAAdfOAADTomAABJnsAAGAAAdfOAAFAlanrowsselected.SQL>deletefromnamesawhererowid>(selectmin(rowid)fromnamesbwhereb.name=a.name);rowsdeleted.SQL>selectrowid,namefromnames;ROWIDNAME------------------ ------------------------------AABJnsAAGAAAdfOAAAAlanAABJnsAAGAAAdfOAACCarrieAABJnsAAGAAAdfOAADTomrowsselected.SQL>commit;Commitcomplete.
Method 4
Deleting Rows with Columns
 Select your rows. After "SQL," enter "select * from names;" to see your rows.
Select your rows. After "SQL," enter "select * from names;" to see your rows.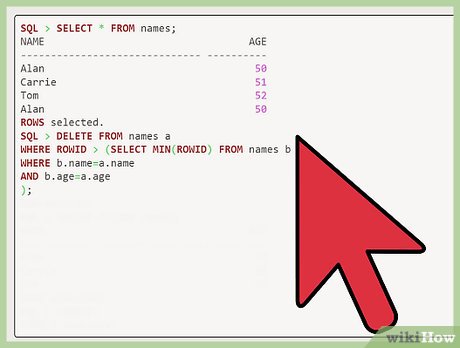 Delete duplicate rows by identifying their column. After "SQL'" enter "delete from names a where rowid > (select min(rowid) from names b where b.name=a.name and b.age=a.age);" to delete the duplicate records.[3]
Delete duplicate rows by identifying their column. After "SQL'" enter "delete from names a where rowid > (select min(rowid) from names b where b.name=a.name and b.age=a.age);" to delete the duplicate records.[3] Check for duplicates. Once you have completed the above steps, enter "select * from names;" and then "commit" to check that you have deleted the duplicate records successfully.
Check for duplicates. Once you have completed the above steps, enter "select * from names;" and then "commit" to check that you have deleted the duplicate records successfully.
SQL>select*fromnames;NAMEAGE------------------------------ ----------Alan50Carrie51Tom52Alan50rowsselected.SQL>deletefromnamesawhererowid>(selectmin(rowid)fromnamesbwhereb.name=a.nameandb.age=a.age);rowdeleted.SQL>select*fromnames;NAMEAGE------------------------------ ----------Alan50Carrie51Tom52rowsselected.SQL>commit;Commitcomplete.
Frequently Asked Questions
What is Name: How to Delete Duplicate Records in Oracle about?
It provides a structured overview of name, explains the main context, and highlights practical takeaways for readers.
Why does this topic matter?
Understanding the main concepts helps readers evaluate the issue, avoid common mistakes, and make better-informed decisions.
How should readers use this information?
Use the guidance as a practical starting point, confirm details that may have changed, and follow current product, safety, or security recommendations.
Was this article helpful?
Your feedback helps us improve.
Related Articles
 How to Delete Duplicate Contacts on Android6 minutes read
How to Delete Duplicate Contacts on Android6 minutes read
 MS SQL Server: DISTINCT Clause in SQL Server3 minutes read
MS SQL Server: DISTINCT Clause in SQL Server3 minutes read
 How to Create Duplicate Search Queries in Access 20166 minutes read
How to Create Duplicate Search Queries in Access 20166 minutes read
 How to for Finding and Deleting Duplicate Files on Windows?5 minutes read
How to for Finding and Deleting Duplicate Files on Windows?5 minutes read
 How to Delete Duplicate Slides on Powerpoint Is Very Simple3 minutes read
How to Delete Duplicate Slides on Powerpoint Is Very Simple3 minutes read
 The Best 5 Apps to Delete Photos on Android6 minutes read
The Best 5 Apps to Delete Photos on Android6 minutes read
Reader Comments 0
Sign in with email or Google to join the discussion.