Data Clusters in Machine Learning
A cluster is a collection of similar data. Clustering is a type of unsupervised learning. The correlation coefficient describes the strength of the relationship.
- A cluster is a collection of similar data.
- Clustering is a type of unsupervised learning.
- The correlation coefficient describes the strength of the relationship.
Data clusters
Clusters are sets of data based on similarity.
Data points grouped together in a chart can often be categorized into clusters.
In the diagram below, we can distinguish three different clusters:
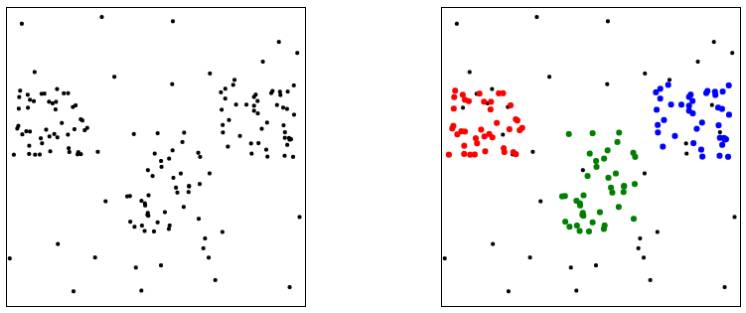
Identify data clusters
Clusters can contain a wealth of valuable information, but they come in many different shapes, so how can we recognize them?
The two main methods are:
- Use visualization
- Using clustering algorithms
Clustering
Clustering is a type of unsupervised learning.
Clustering aims to:
- Collect similar data into groups.
- Collect dissimilar data into other groups.
Clustering methods
- Density method
- Hierarchical method
- Partitioning method
- Grid-based method
Density methods consider points in high-density regions to have more similarities and differences compared to points in lower-density regions. Density methods have good accuracy. They also have the ability to merge clusters. Two popular algorithms are DBSCAN and OPTICS.
Hierarchical clustering methods create clusters in a tree-like structure. New clusters are formed by utilizing previously formed clusters. Two popular algorithms are CURE and BIRCH.
Grid-based methods format data into a finite number of cells forming a grid structure. Two common algorithms are CLIQUE and STING.
Partitioning methods divide objects into k clusters, with each partition forming a cluster. A common algorithm is CLARANS.
Correlation coefficient
The correlation coefficient (r) describes the strength and direction of the linear relationship between the x/y variables on the scatter plot .
The value of r is always between -1 and +1:
| -1.00 | Completely downhill | Inverse linear relationship. |
| -0.70 | Steep slope | Inverse linear relationship. |
| -0.50 | A moderate slope | Inverse linear relationship. |
| -0.30 | A gentle slope | Inverse linear relationship. |
| 0 | There is no linear relationship. | |
| +0.30 | Slightly uphill | The relationship is linearly positive. |
| +0.50 | Moderate incline | The relationship is linearly positive. |
| +0.70 | Steep uphill | The relationship is linearly positive. |
| +1.00 | Uphill | The relationship is linearly positive. |
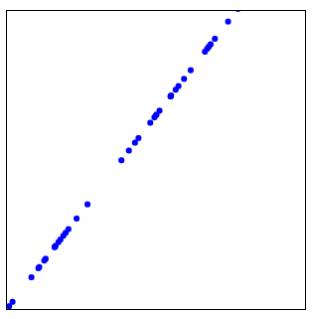
Full uphill slope +1.00:
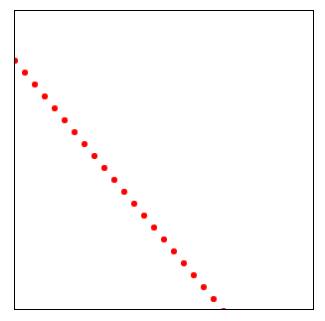
A full drop to -1.00:
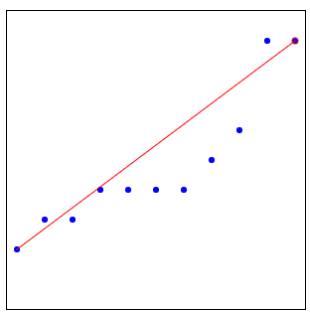
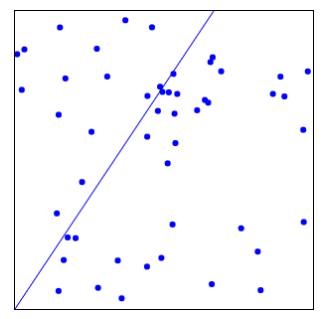
Strong upward slope of +0.61:
There is no linear relationship:
- Line Learning Data
- Machine Learning Terminology
- Learn Machine Learning
- The best Python tools for Machine Learning and Data Science
- [Infographic] AI and Machine Learning in the enterprise
- What is machine learning? What is deep learning? Difference between AI, machine learning and deep learning
- Machine Learning in JavaScript
- 7 practical applications of Machine Learning
- Google released the TensorFlow machine learning framework specifically for graphical data
- The difference between AI, machine learning and deep learning
- Machine Learning in JavaScript
- 3 benefits of AI with businesses in the future
- Google launched TensorFlow Lite 1.0 for mobile devices and embedded devices
- Train AI tools without knowing code with Google's new tool
- Nvidia launched the worst graphics processor ever
- Deep Learning - new cybersecurity tool?
- Magic: The Gathering - the most difficult 'chew' game for all AI models
- AI uses tweets to help researchers analyze the flood situation
- Improve the effectiveness of assessing depression status by AI models
- Google released a huge AI training data warehouse with over 5 million photos of 200,000 locations worldwide
 Important lessons from a failed marriage
Important lessons from a failed marriage 4 Tips to Make Your Long-Distance Relationship Work During the Pandemic
4 Tips to Make Your Long-Distance Relationship Work During the Pandemic How to Overcome a 3-Year Crisis in a Relationship
How to Overcome a 3-Year Crisis in a Relationship How to Create Your Ideal Relationship
How to Create Your Ideal Relationship How to Make a Relationship Better
How to Make a Relationship Better How to Detect a Playgirl
How to Detect a Playgirl