AI benchmark scores are meaningless: Pay attention to the following!
Performance benchmarks aren't useless. The problem is they're serving the wrong audience, acting more like marketing than clearly explaining what's new, what works, and how it will save you time..
Whenever a new AI model is released, a plethora of AI performance comparison websites pop up, bombarding us with colorful charts, highlighting minor and insignificant improvements with numbers that aren't put into context and are essentially meaningless to most people.
For the most part, unless you're an AI researcher, most of these statistics and charts are meaningless. Those numbers often don't reveal information relevant to how most people use AI .
Performance benchmarks aren't useless. The problem is they're serving the wrong audience, acting more like marketing than clearly explaining what's new, what works, and how it will save you time.
Why do AI companies love performance comparison charts?
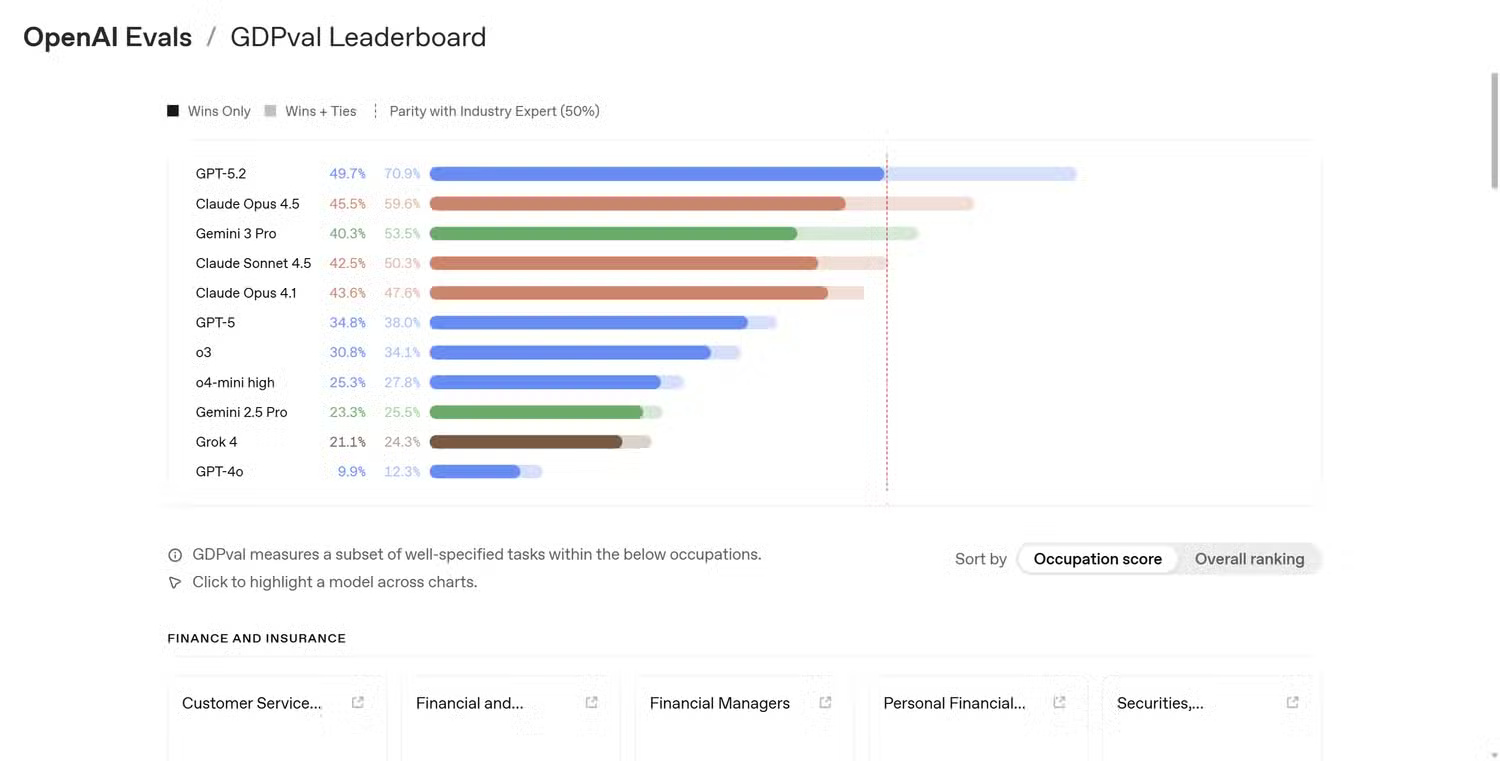
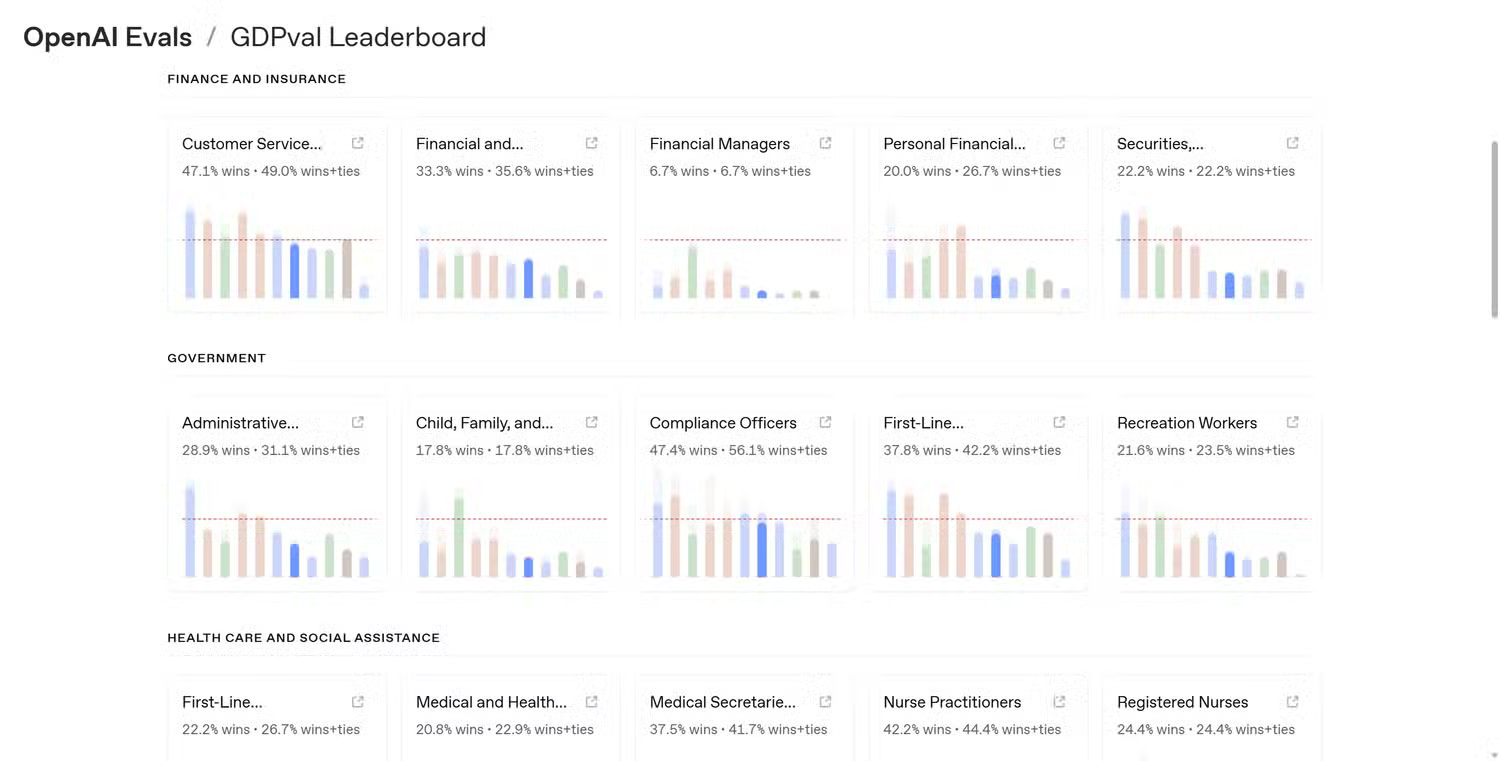
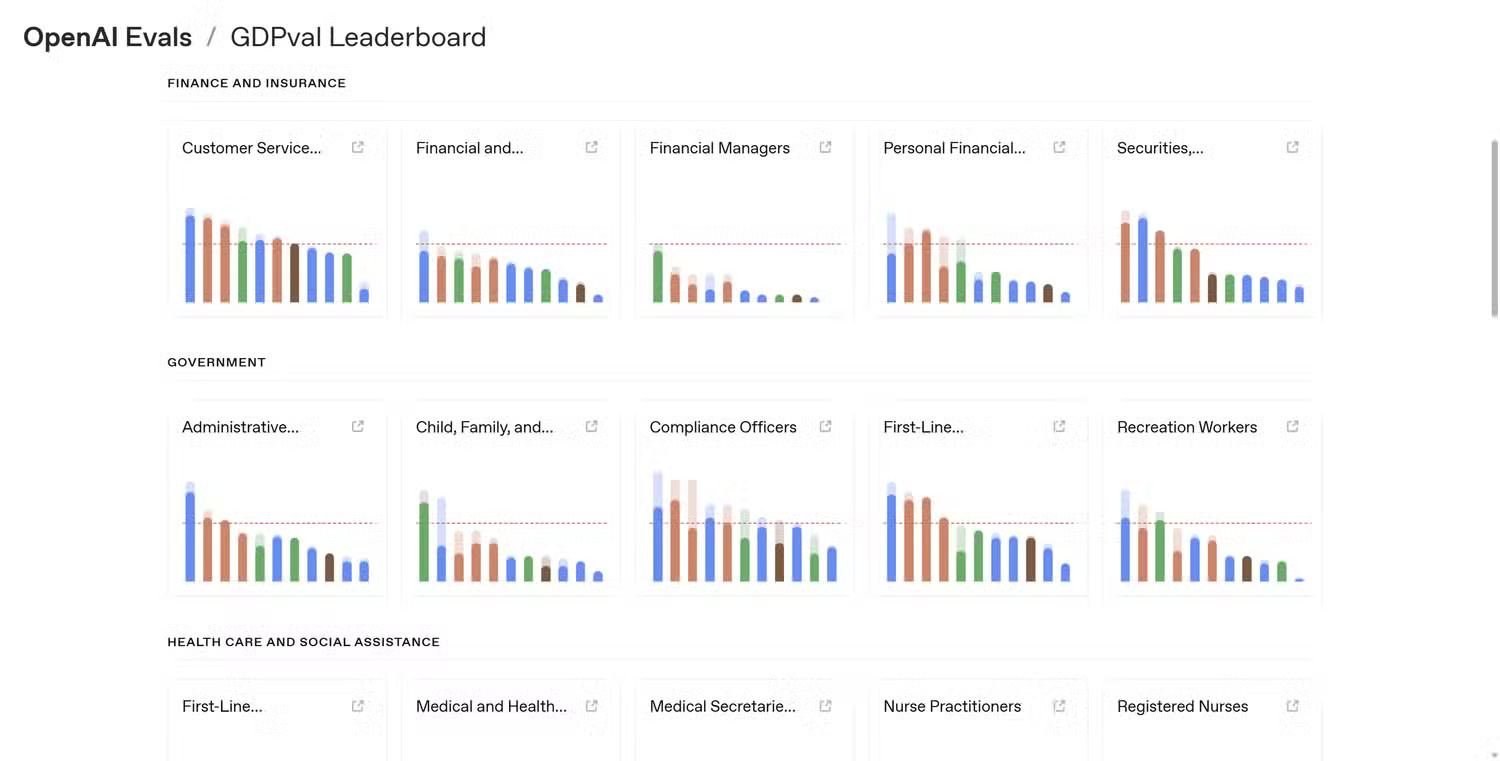
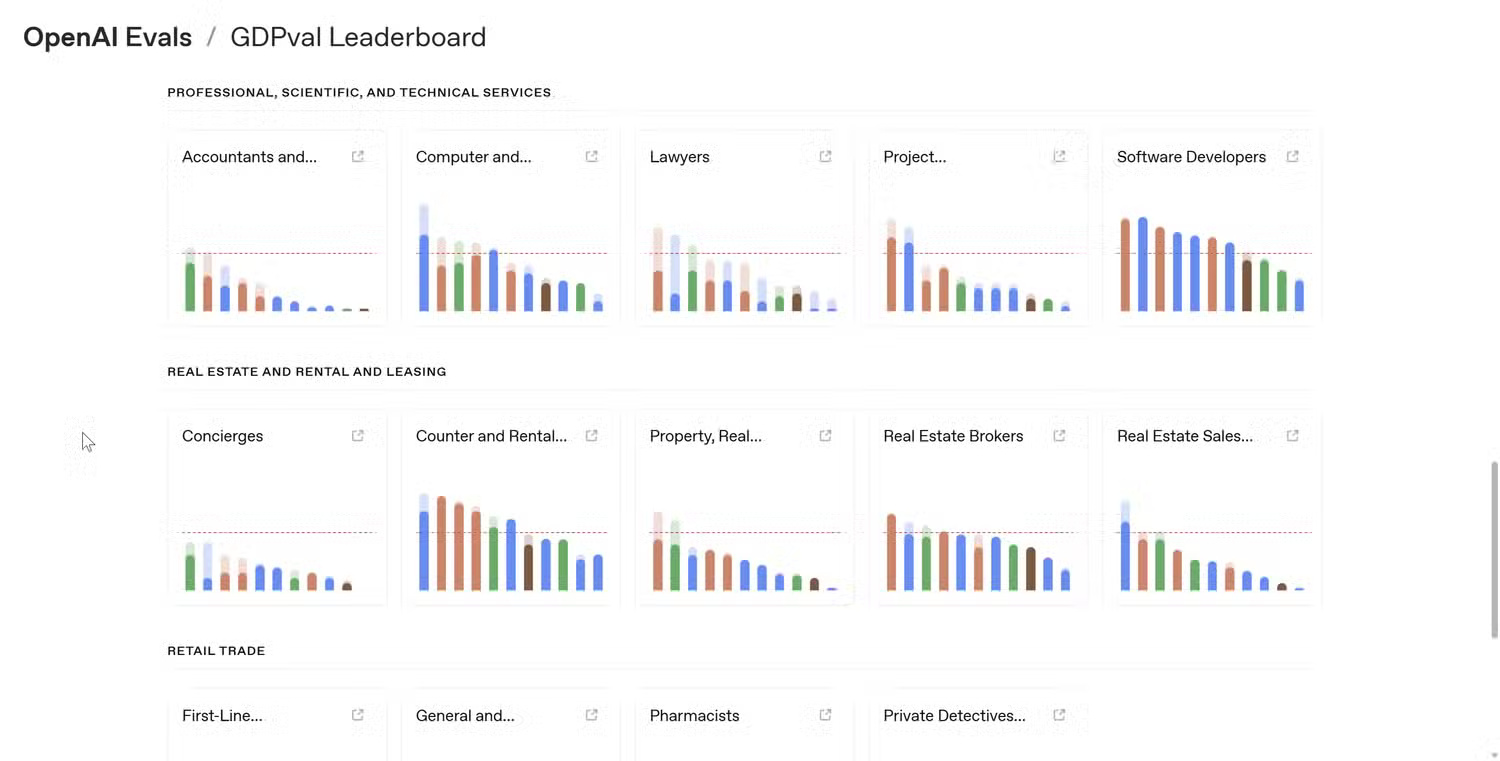
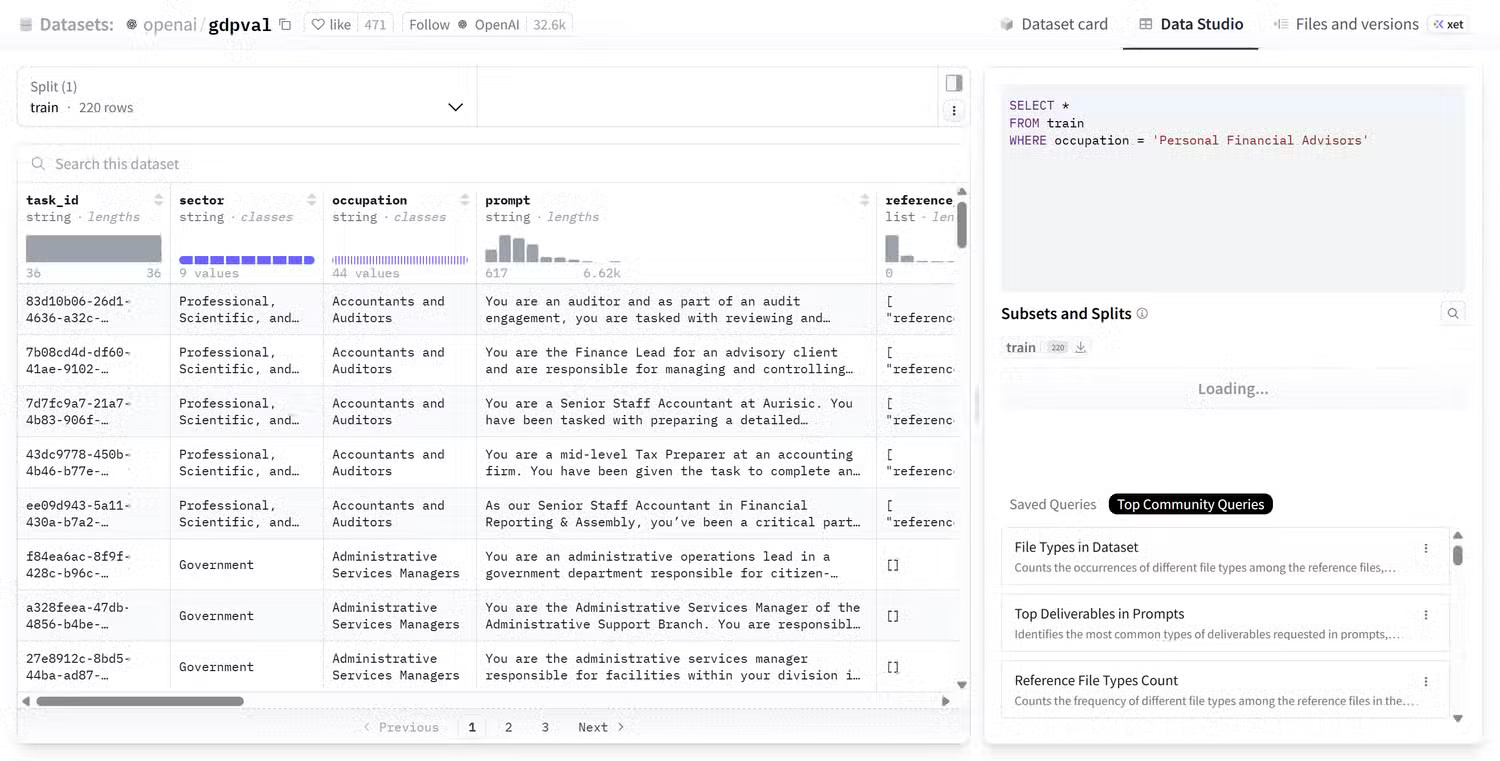
The rationale behind comparing AI performance, like all other performance benchmarks, is logical. They simplify complex systems into easily understandable numbers. Instead of describing small improvements in reasoning or language comprehension, companies can point to a graph and say their model scored 92% in a test while their competitor scored 88%.
Comparisons are objective, and evaluation criteria provide a standardized method for managing performance and datasets in a controlled environment. If every lab evaluates its model using the same test, it becomes easier to track progress and measure improvements across different methods.
The problem is that as soon as these evaluation standards leave the lab and are used in real-world situations, the context behind them often becomes meaningless. One model outperforming another in a reasoning ability assessment doesn't necessarily mean it will perform better in everyday tasks like summarizing documents, editing text, or answering complex questions.
For most people, these capabilities are far more important than performance on carefully structured datasets in a tightly controlled laboratory environment.
What do AI evaluation standards actually test?
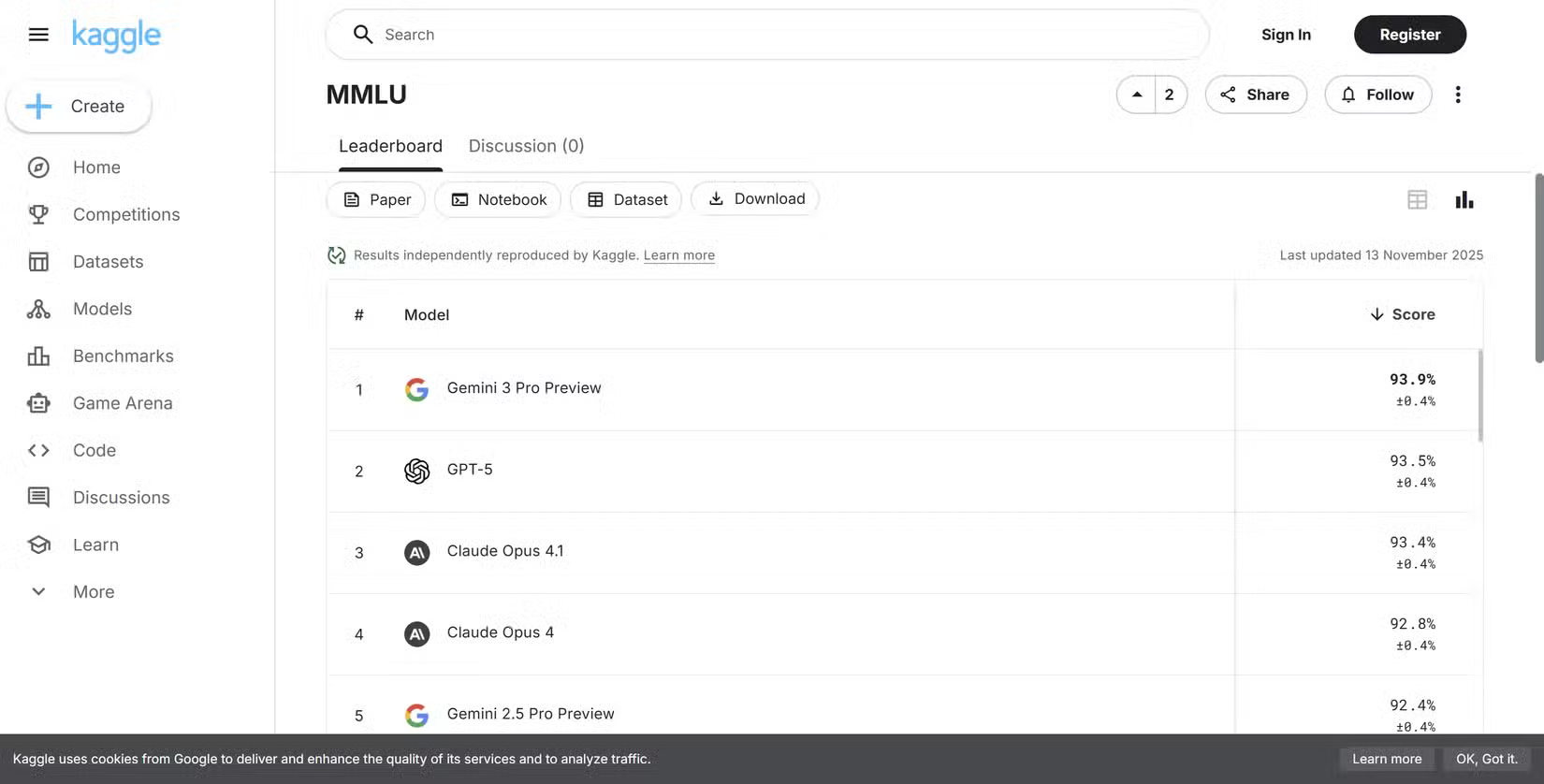
What makes evaluating AI performance even more complicated is the sheer number of tests from both AI developers and external testing firms. But the easiest way to understand real-world usefulness is to examine what they are measuring.
Because testing is standardized, there are a few widely used AI performance evaluation tests.
- MMLU : The Massive Multitask Language Understanding test assesses models using thousands of multiple-choice questions across dozens of subjects, including physics, law, economics, biology, and medicine.
- GSM8K : Grade School Math 8K is a math test that measures mathematical reasoning ability, with a dataset containing thousands of elementary school math puzzles that require multiple steps to solve.
- HumanEval : The HumanEval test examines models using programming prompts and evaluates whether the AI can produce an accurate solution that passes a series of tests. This makes it extremely valuable in evaluating models to assist programmers.
In theory, it's all useful. But in practice, applying it to the real world isn't easy. For example, while MMLU sounds impressive, it essentially just answers a huge list of test-style questions with predefined answers. But most people don't use AI to take tests—they're using it to understand instructions and solve problems. Furthermore, MMLU has a high error rate and a significant bias towards the West.
Similarly, GSM8K is a useful indicator of logical reasoning ability, but most people don't use AI chatbots to solve basic arithmetic problems. They ask them to explain concepts, summarize information, compose content, or assist with research, yet GSM8K scores still frequently appear in marketing materials as proof of general intelligence.
Benchmark contamination is a major problem.
Another major problem with AI performance evaluation is dataset contamination.
Most AI models are trained using vast collections of text and other information gathered from the internet . This means the datasets include research papers, textbooks, online code repositories, and many publicly available standard datasets.
When benchmark questions appear in the training data, the models can effectively memorize the answers.
Researchers call this phenomenon contamination, and it can significantly skew performance evaluations. A model might perform well on a test not because it has learned how to reason to solve the problem, but because it has encountered that question before during training.
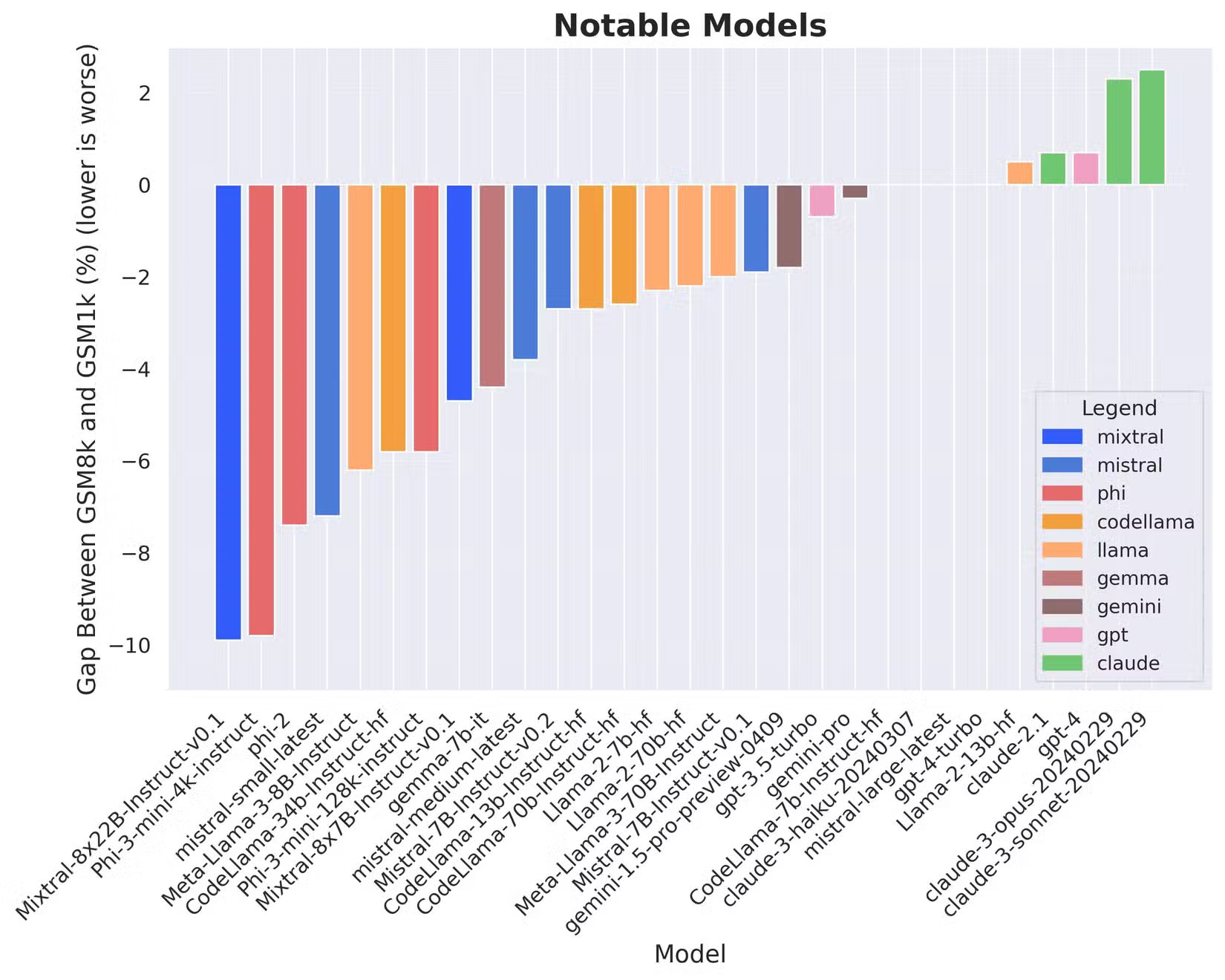
A research paper titled "Careful Examination of the Performance of Big Language Models on Elementary-Level Arithmetic Problems" (ArXiv) explored this issue in more detail by testing AI models on GSM1K, an AI performance test similar to GSM8K that the researchers can assure we have never used before.
The study found that some models, such as Phi, Mistral, and Llama, "are exhibiting evidence of systematic overfitting across almost every model size," with accuracy decreasing "up to 13%" when tested on a similar but untested standard dataset.
Further analysis revealed a positive correlation (Spearman correlation coefficient r2=0.32) between a model's probability of generating an example from GSM8k and the performance gap between GSM8k and GSM1k, suggesting that many models may have partially memorized GSM8k.
Therefore, while performance tests can quickly reveal performance, it's still possible that the AI model's performance is enhanced by its existing knowledge of the questions and answers. That's why this research is crucial for accuracy, and why AI performance tests don't always accurately reflect reality.
AI benchmarks you should really care about.
Performance tests aren't pointless. Having ways to make complex datasets understandable isn't a bad thing—that's not what we're arguing here. It's just that other benchmarks and analytics make more sense for the average user.
Some leverage the collective experience of AI chatbot users, while others focus more on everyday issues we encounter, such as hallucinations.
1. Examine people's preferences.
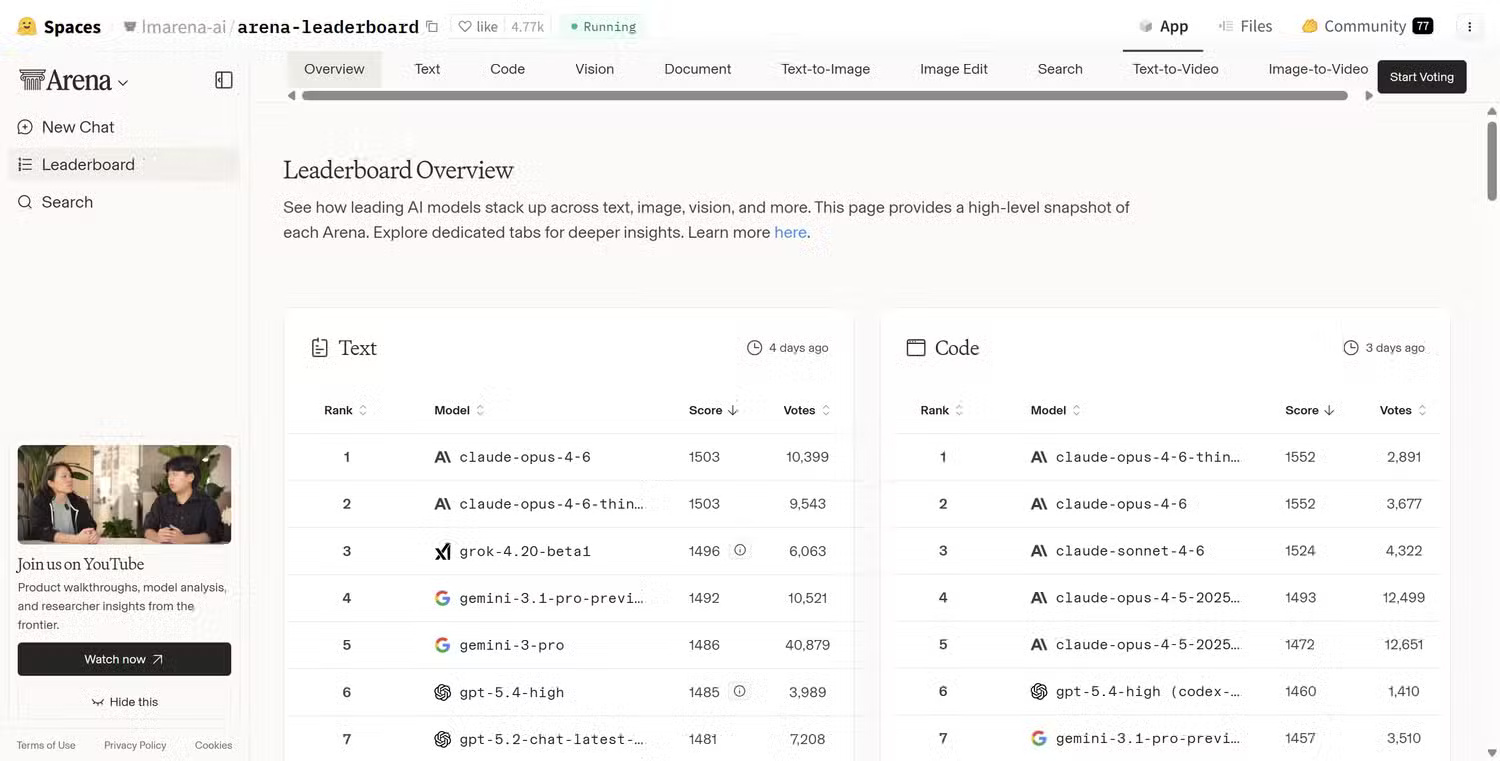
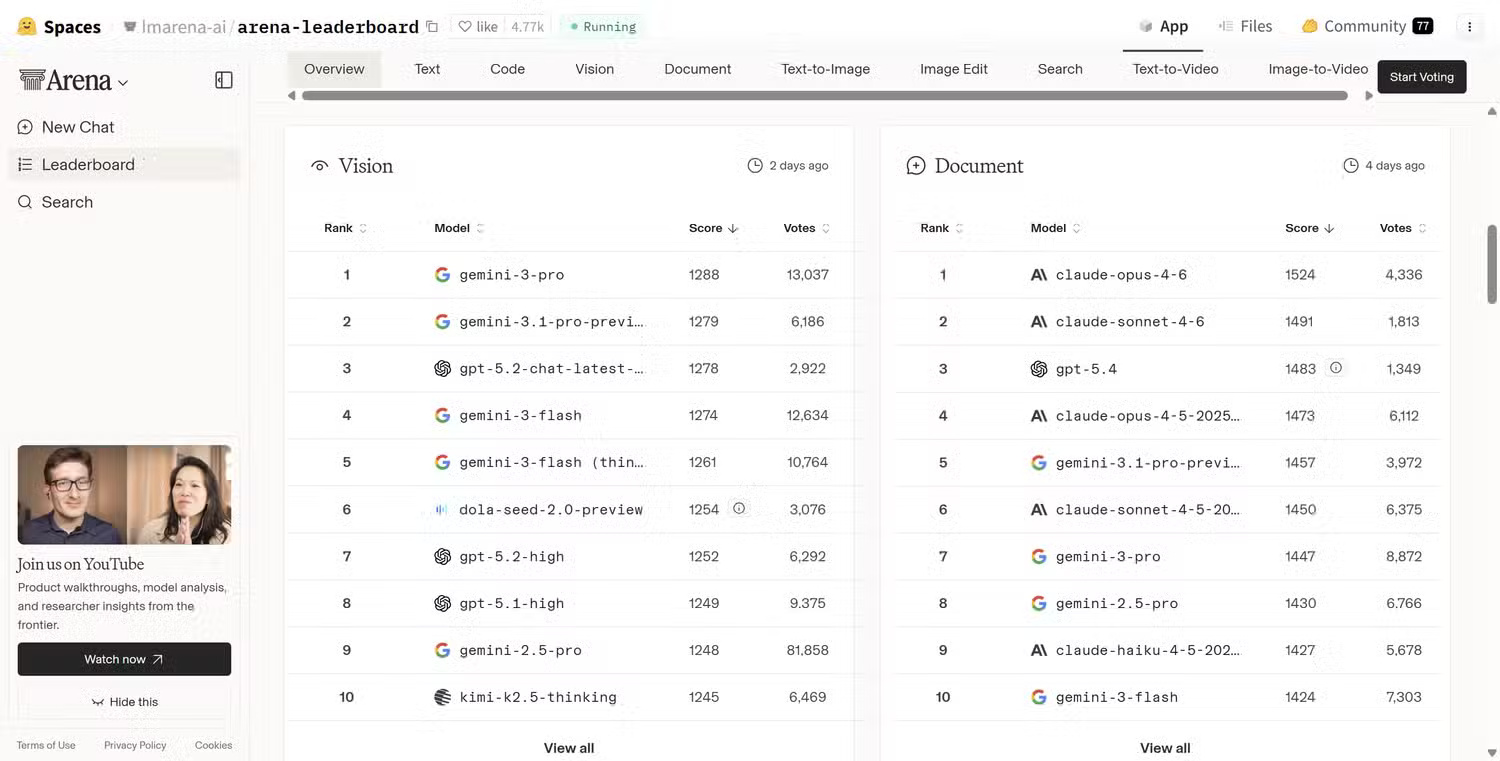
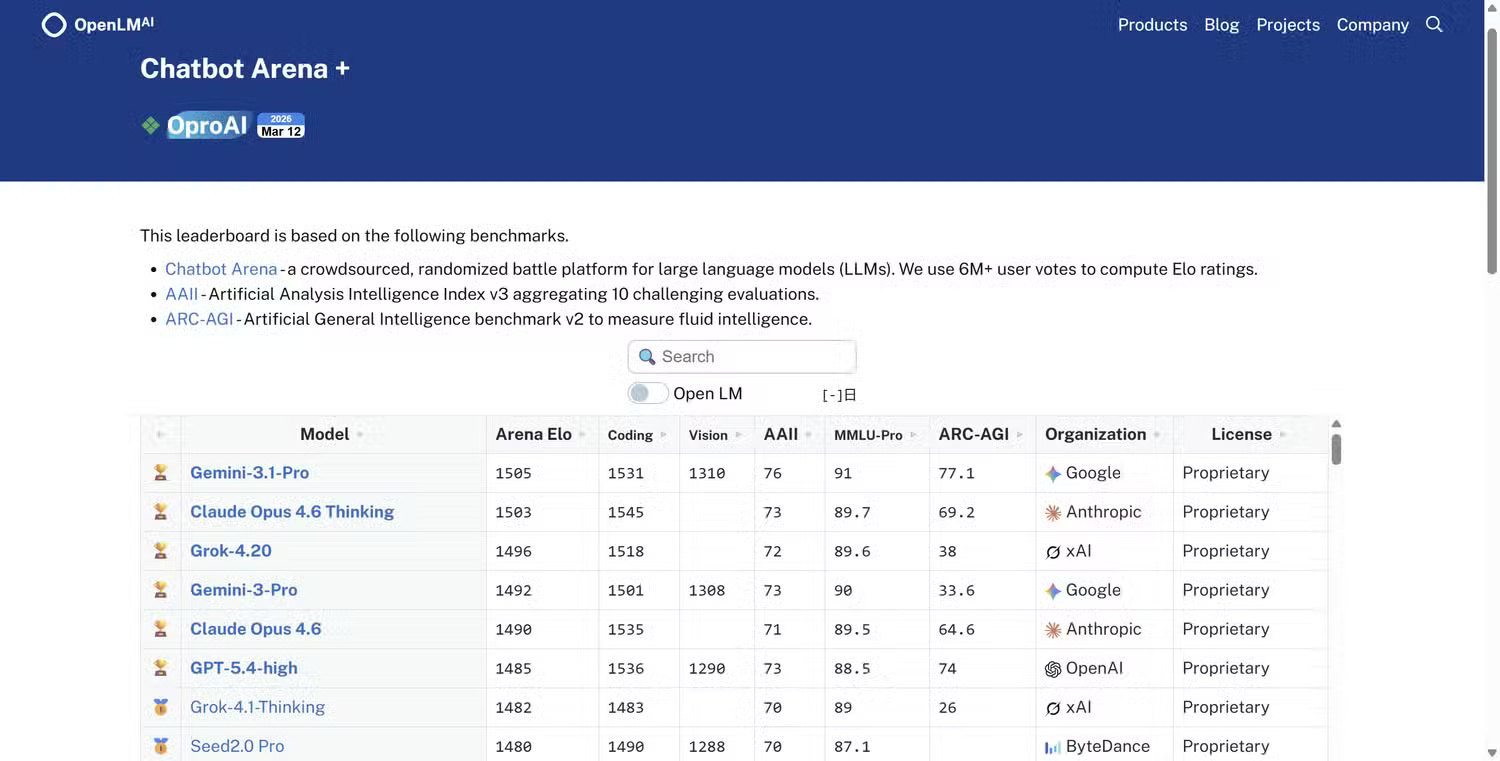
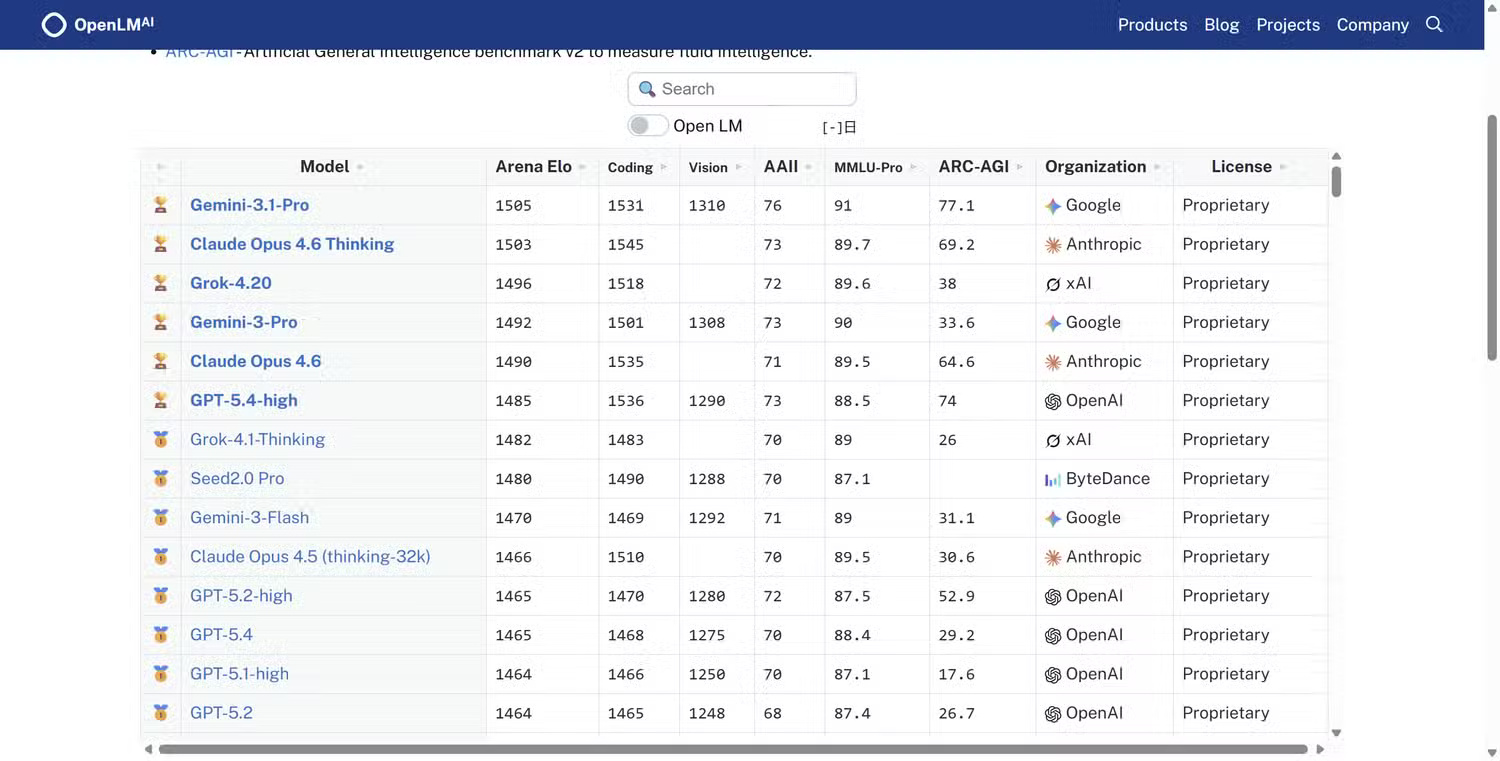
One of the most widely used alternatives to conventional AI standards is websites that test human preferences, comparing blind human ratings.
Websites like Hugging Face's Leaderboard Overview , OpenLM's Chatbot Arena , and ArenaAI's Battle Mode give you a much better chance to find out the true value of AI to humans.
In most cases, you pose a question, two AI models generate answers, and then people vote on the answers. Because the models are anonymous, voters don't know which system generated which answer. This reduces brand bias and focuses the evaluation on the actual quality of the output.
Over time, the system collects hundreds of thousands of votes and creates rankings based on users' actual preferences.
This approach captures what traditional standards often miss, such as clarity, usefulness of the answer, ability to follow instructions, conversational tone, etc.
In other words, it assesses the experience of using the model, not just the ability to pass academic tests.
2. International Fair Fair Compliance (IFEval)
Another alternative AI comparison evaluation method is IFEval, an AI evaluation tool developed by experts at Google , but it is also not officially supported by Google.
Instead of testing knowledge or reasoning ability, IFEval measures something much simpler: Does the model actually follow the instructions?
For example, prompts might include measures such as answering directly in 5 points, writing answers in JSON format, avoiding specific words or characters, limiting the length or character count of the answer, etc.
Tests of this type are crucial because they are the kind of instructions people give to AI chatbots every day. The standard then checks whether the model meets those standards.
This may sound basic, but reliability in following instructions is one of the most important factors in a real-world AI workflow.
3. High-Level Practical Task Assessment (HELM) Standards

Another effort to evaluate AI models more realistically is the Holistic Evaluation of Language Models (HELM) framework, developed by researchers at the Stanford Foundation Center for Modeling Research .
HELM is particularly useful because, instead of focusing on a single score in a controlled laboratory environment, it evaluates models across multiple real-world scenarios, including:
- Summary of tasks
- Answer the question
- Extract information
- Toxic and biased
- Ability to adapt to prompt changes
HELM also measures additional attributes besides accuracy, such as:
- Calibration (reliability versus accuracy)
- Fairness
- Effectiveness
- Adaptability
The idea is that evaluating a language model requires considering multiple aspects, not just a single score on a ranking chart.
4. TruthfulQA
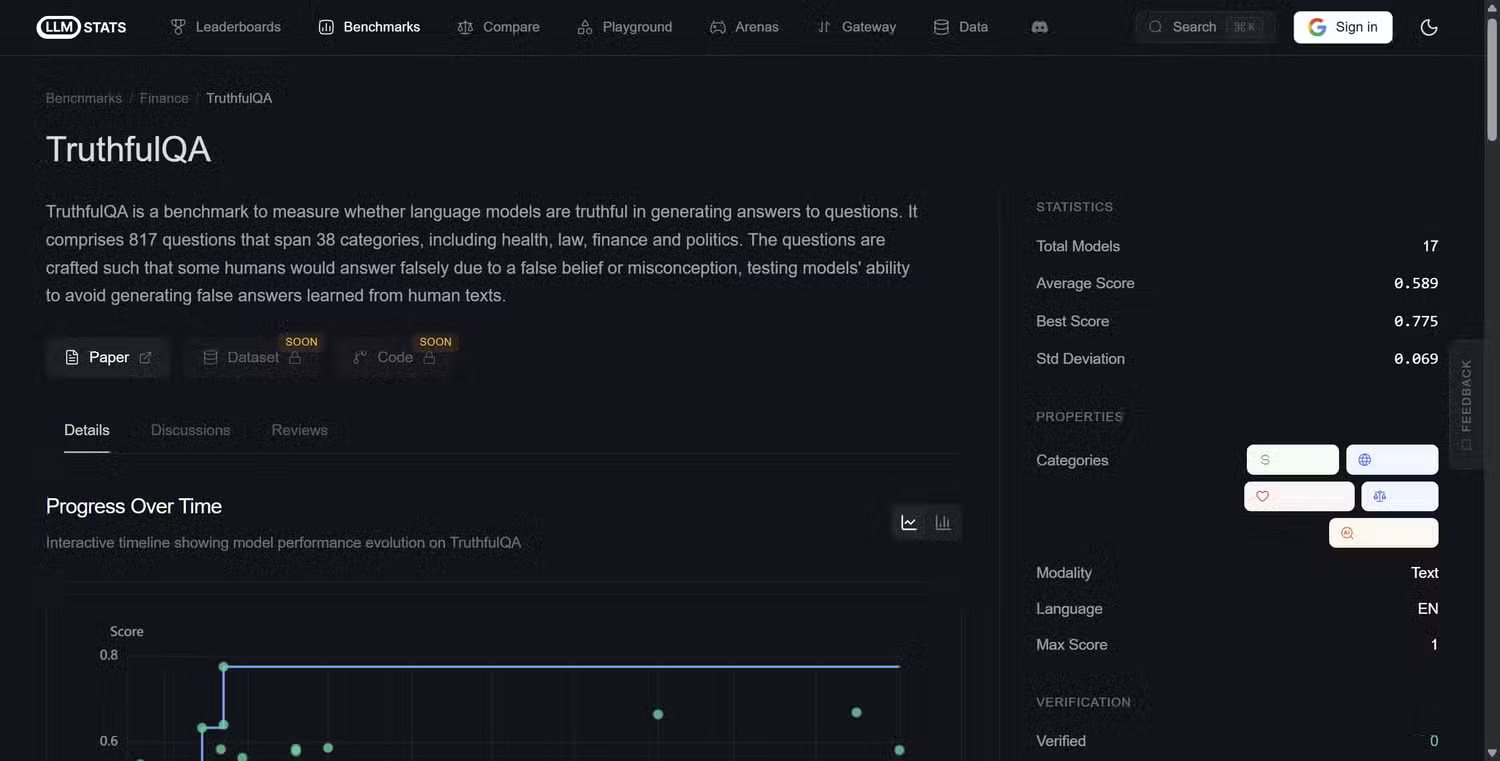
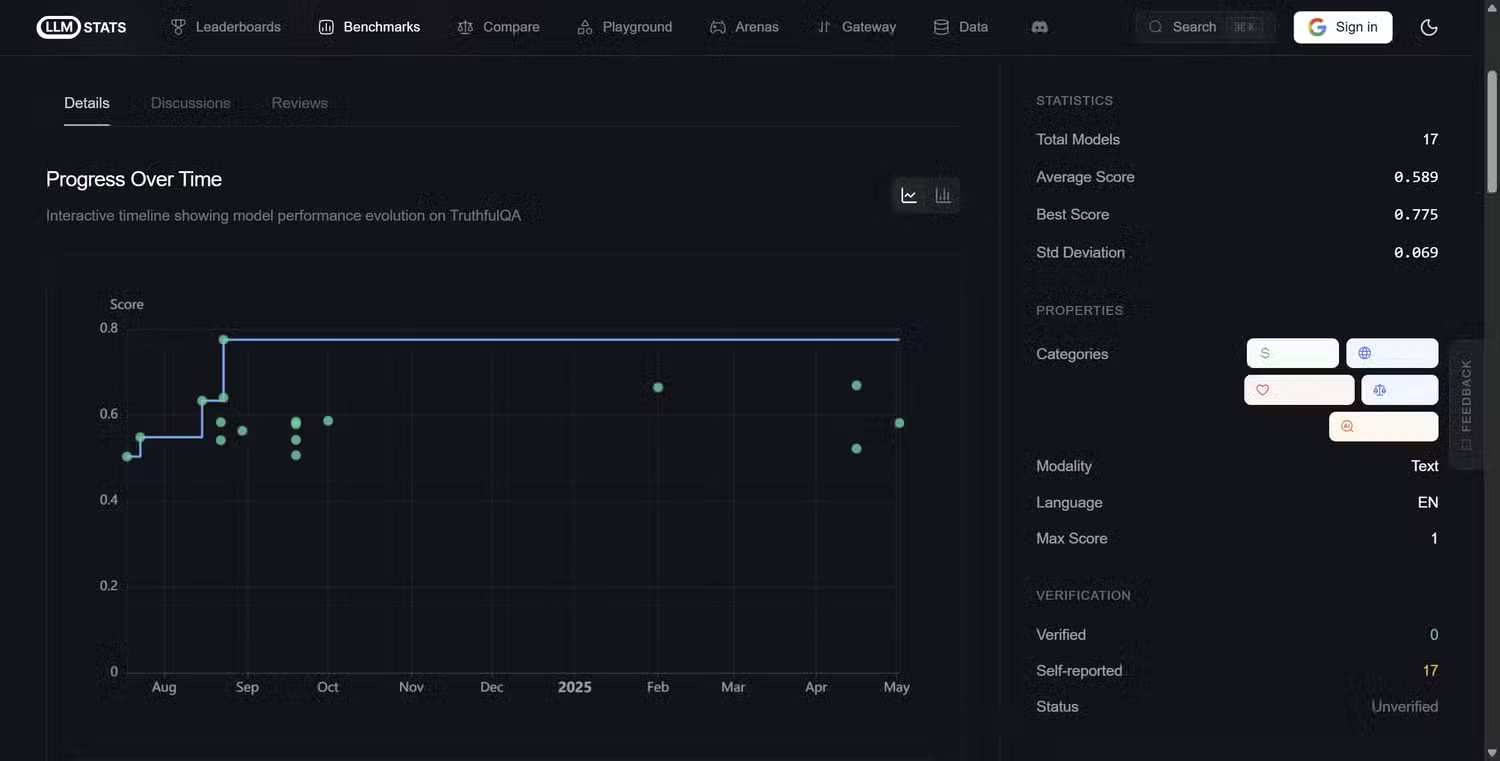
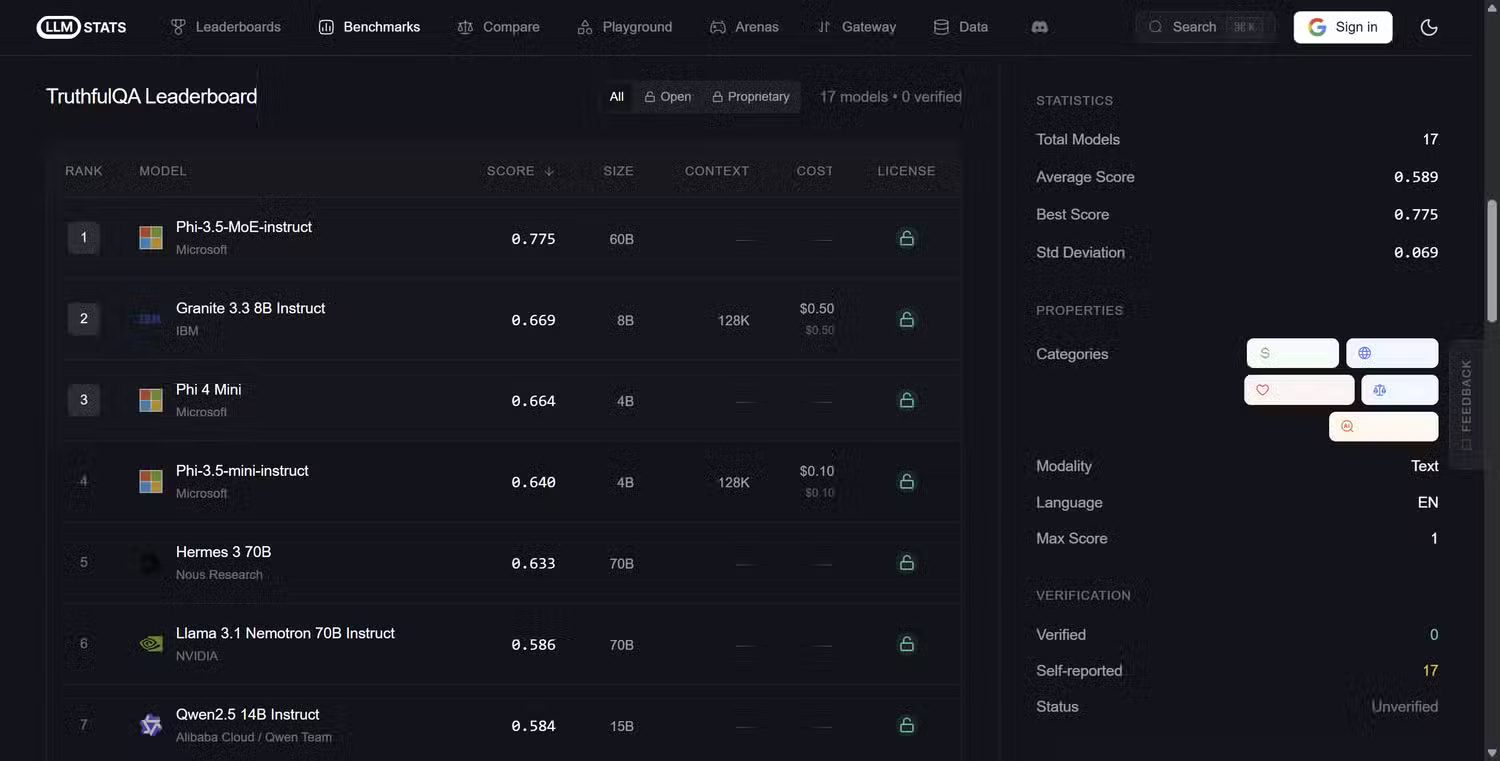
Ultimately, one of the biggest problems with Generative AI is hallucination, where the model essentially lies and gives incorrect, misleading, or completely fabricated answers.
As you might expect, it's crucial to understand whether the tool you're using is providing unsubstantiated information, which is why the TruthfulQA standard tests questions that commonly lead to misconceptions or incorrect answers. The test assesses whether the model replicates those misconceptions or avoids them correctly, using 817 questions across 38 categories including myths, conspiracy theories, misinformation, trick questions, etc.
TruthfulQA is actually one of the most popular AI illusion performance assessment tools, with over 5,000 citations on Google Scholar, and the main metric it measures is honesty: does the model provide a realistically accurate answer or does it confidently produce something wrong?