How to use Scikit-LLM to analyze text with large language models
Powerful language models + Scikit-learn = Scikit-LLM. This library will help you implement text analysis tasks quickly..
Powerful language models + Scikit-learn = Scikit-LLM . This library will help you implement text analysis tasks quickly.

Scikit-LLM is a Python package that helps integrate Large Language Models (LLM) into the scikit-learn framework. It helps complete text analysis tasks. If you are familiar with scikit-learn, working with Scikit-LLM will be easier.
It's important to keep in mind that Scikit-LLM does not replace scikit-learn. scikit-learn is a general-purpose machine learning library but Scikit-LLM is specifically designed for text analysis tasks.
Instructions for using Scikit-LLM
To start using Scikit-LLM, you need to install the library and configure an API key. To install this library, open the IDE and create a new virtual environment. This helps prevent potential library version conflicts. Then, run the following command in terminal.
pip install scikit-llmThis command will install Scikit-LLM and the necessary dependencies.
To configure an API key, you need to get one from the LLM provider. To get your OpenAI API key, follow these steps:
Continue to the OpenAI API page . Then, click on the profile located in the upper right corner of the window. Select View API keys . This will take you to the API keys page .

On the API keys page , click the Create new secret key button .

Name the API key and click the Create secret key button to create the key. Once created, you need to copy the key and store it in a safe place because OpenAI will not show the key again. If you lose it, you need to create a new key.
Now that you have your API key, open the IDE and import the SKLLMConfig class from the Scikit-LLM library . This class allows you to set configuration options related to the use of major language models.
from skllm.config import SKLLMConfigThis class requires you to set your OpenAI API key and organization details.
# Đặt key OpenAI API SKLLMConfig.set_openai_key("Your API key") # Thiết lập tổ chức OpenAI SKLLMConfig.set_openai_org("Your organization ID")Organization ID and name are not the same. The organization ID is a unique identifier for your organization. To get the organization ID, go to the OpenAI Organization settings page and copy it. You have now established a connection between Scikit-LLM and the large language model.
Attempting to use a free trial account will generate an error similar to the image below while performing data analysis.

Import the necessary libraries and load the dataset
Enter the pandas you will use to load the dataset. Additionally, from Scikit-LLM and scikit-learn, import the required classes:
import pandas as pd from skllm import ZeroShotGPTClassifier, MultiLabelZeroShotGPTClassifier from skllm.preprocessing import GPTSummarizer from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.preprocessing import MultiLabelBinarizer Next, load the dataset you want to perform analysis. This code uses the movie dataset on IMDB. However, you can tweak it to use your own data set.
# Tải dataset data = pd.read_csv("imdb_movies_dataset.csv") # Truy xuất 100 hàng đầu tiên data = data.head(100)It is not required to use only the first 100 rows in the dataset. You can use the entire dataset.
Next, retrieve the features and label the columns. Then, split the dataset into two parts: train and test.
# Truy xuất các cột liên quan X = data['Description'] # Assuming 'Genre' contains the labels for classification y = data['Genre'] # Tách dataset thành train và test X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)The Genre column contains the labels you want to predict.
Classify zero-shot text using Scikit-LLM
Zero-shot text classification is a feature provided by major language models. It classifies text into predefined categories without explicit training on labeled data. This capability is very useful when dealing with tasks where you need to classify text into categories that were not anticipated during model training.
To perform zero-shot text classification with Scikit-LLM, use the ZeroShotGPTClassifier class.
# Tiến hành phân loại văn bản Zero-Shot zero_shot_clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo") zero_shot_clf.fit(X_train, y_train) zero_shot_predictions = zero_shot_clf.predict(X_test) # In báo cáo phân loại text Zero-Shot print("Zero-Shot Text Classification Report:") print(classification_report(y_test, zero_shot_predictions))
The following results:
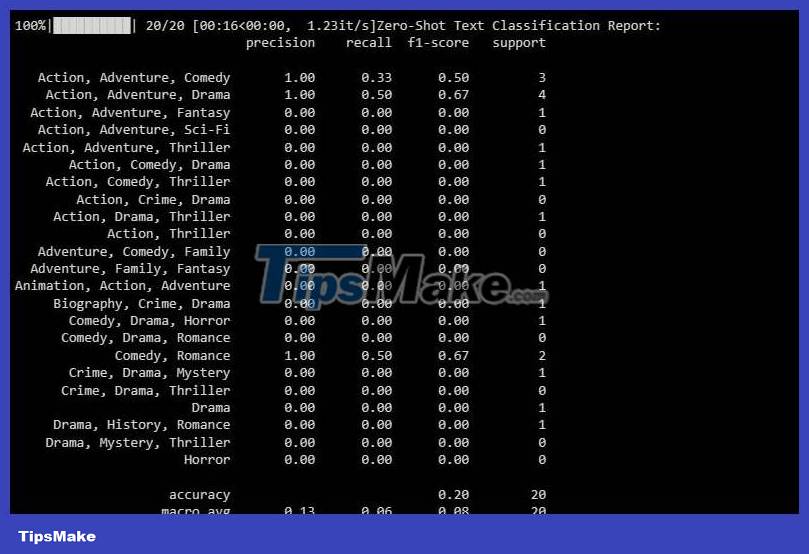
This classification report provides metrics for each label the model is trying to predict.
Multi-label zero-shot text classification using Scikit-LLM
In some cases, a text can belong to multiple categories at the same time. Traditional classification models have difficulty handling these cases. On the other hand, Scikit-LLM makes it possible to classify them. Multi-label zero-shot text classification is extremely important in assigning multiple descriptive labels to a text sample.
Use MultiLabelZeroShotGPTClassifier to predict suitable labels for each text sample.
# Triển khai phân loại văn bản Zero-Shot đa nhãn # Đảm bảo cung cấp danh sách các nhãn candidate candidate_labels = ["Action", "Comedy", "Drama", "Horror", "Sci-Fi"] multi_label_zero_shot_clf = MultiLabelZeroShotGPTClassifier(max_labels=2) multi_label_zero_shot_clf.fit(X_train, candidate_labels) multi_label_zero_shot_predictions = multi_label_zero_shot_clf.predict(X_test) # Chuyển đổi nhãn sang định dạng mảng nhị phân bằng MultiLabelBinarizer mlb = MultiLabelBinarizer() y_test_binary = mlb.fit_transform(y_test) multi_label_zero_shot_predictions_binary = mlb.transform(multi_label_zero_shot_predictions) # In báo cáo phân loại văn bản Zero-Shot đa nhãn print("Multi-Label Zero-Shot Text Classification Report:") print(classification_report(y_test_binary, multi_label_zero_shot_predictions_binary))In the above code block, you define the candidate labels to which the text belongs.
The following results:
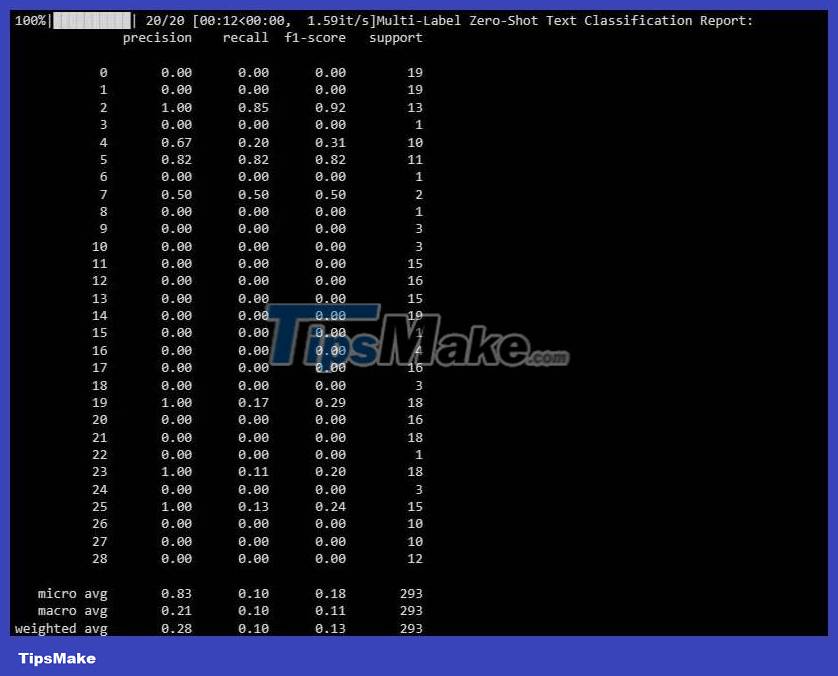
This report helps you understand how well the model is performing for each label in a multi-label classification.
Text Vectorization with Scikit-LLM
In text vectorization, text data is converted into a numeric format that machine learning models can understand. Scikit-LLM provides a GPTVectorizer to perform this task. It allows you to convert text into fixed-dimensional vectors using GPT models.
You can achieve this using Term Frequency-Inverse Document Frequency.
# Thực hiện Vector hóa văn bản bằng TF-IDF tfidf_vectorizer = TfidfVectorizer(max_features=1000) X_train_tfidf = tfidf_vectorizer.fit_transform(X_train) X_test_tfidf = tfidf_vectorizer.transform(X_test) # In các đặc điểm vectơ TF-IDF cho một vài mẫu đầu tiên print("TF-IDF Vectorized Features (First 5 samples):") print(X_train_tfidf[:5]) # Change to X_test_tfidf if you want to print the test setResult:
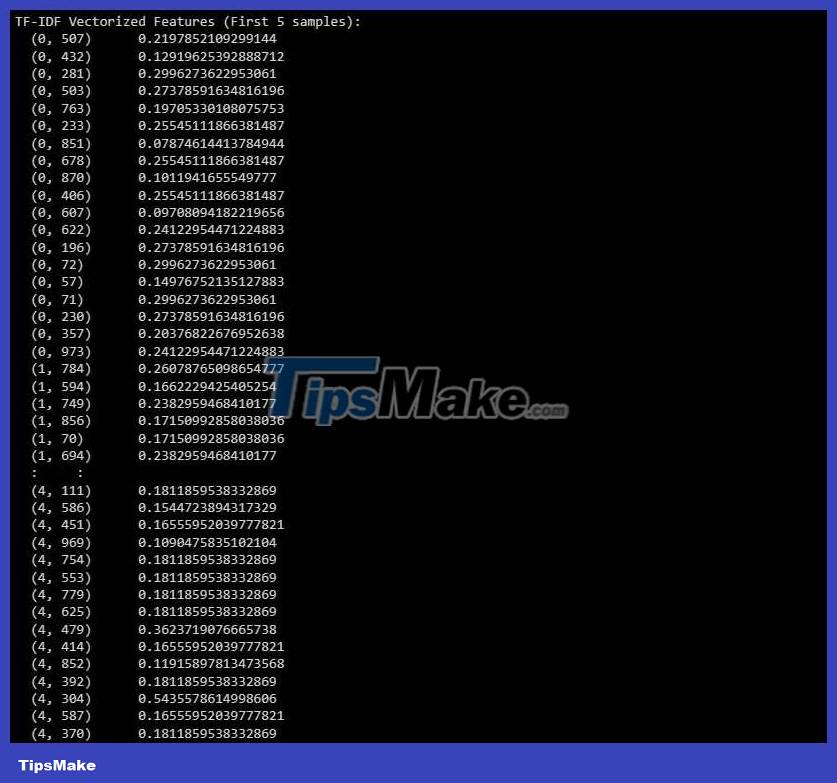
This result represents the TF-IDF vectorized features for the first 5 samples in the dataset.
Text summarization using Scikit-LLM
Text summarization helps condense a piece of text, while still retaining the most important information. Scikit-LLM provides GPTSummarizer, which uses GPT models to generate accurate text summaries.
# Tiến hành tóm tắt văn bản summarizer = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=15) summaries = summarizer.fit_transform(X_test) print(summaries)Result:

Above is how to use Scikit-LLM to analyze text with large language models. Hope the article is useful to you!