Crowd computing
The 'crowd-based' solution is not new, this is the foundation of open source software. But it is only known for the term 'crowdsourcing' (a combination of 'crowd' - 'crowd' and 'outsourcing') ...
Human-machine collaboration will create a transcendental platform that gathers global knowledge and computing resources?
In the TV game show 'Who is a millionaire? 'There is a help for the candidate: ask the audience the answer. Statistics show that 95% of the audience's answers are correct.

Image for illustrative purposes.
The 'crowd-based ' solution is not new, this is the foundation of open source software. But it is only widely known for the term ' crowdsourcing ' ( crowd-based ' crowd ' and ' outsourcing ') after being introduced by Jeff Howe in the article 'The Rise of Crowdsourcing'. Wired magazine in June 2006.
However, recently, thanks to the development of technology and web platform, 'networking' becomes easy and widespread, new crowdsourcing application becomes attractive. It can be said that the race houses 'chase after the crowd ', from fashion design (Threadless.com, Fashionstake.com) to mobilize capital (Kickstarter.com, Marketocracy.com) and even automobile production. (Rockwellautomation.com), . And there's the 'crowd market' - Mechanical Turk (www.mturk.com, from Amazon), where you can get the work order at the same rate, there will be 'crowd of workers' intellectuals' complete the work for you.
Related terms - Social computing
Social computing or social computing generally encompasses any technology that involves communication and interaction between people through computers (directly or indirectly). In the 'narrow' sense, social computing refers to technologies that support social activities such as blogs, emails, IM (chat), wikis, etc. Deeper, it covers any technology for the implementation of calculations by the 'active member' community - those who not only use (benefit) the application but also create value through content contributions, tagging (tag), ranking, linking and even software components.
The crowd is not only . crowded!
Social network - an application model crowdsourcing. The community uses social networks like Facebook, Twitter, LinkedIn . not only to use but also to create value for these networks through content contribution, analysis, evaluation and even collaborative work. Even the online community helps make decisions or solve complex problems.
The sentence 'follow the crowd' may have to be reviewed. If the TV game statistics are not convincing, Wikipedia - the open encyclopedia - is a powerful demonstration of crowd intelligence.
In the book 'The Wisdom of Crowds' , published in 2004, James Surowiecki provides many evidence that the gathering of knowledge of the majority can yield better results than the thought of few people, even experts. family.
However, Surowiecki himself and many other scholars also point out the circumstances of the crowd's intelligence being trapped. In particular, if some individuals have too much influence on those around them, it is possible to activate the " herd " instinct.
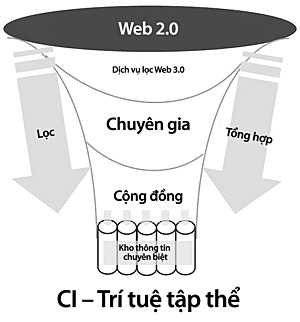 But the 'truth ' still belongs to the crowd! Researchers from the Massachusetts Institute of Technology (MIT) have demonstrated that as the crowd expands (the larger the number of members), the more likely it is to 'converge' exactly the information scattered in the community. even if each member only observes what is near them (within a narrow range).
But the 'truth ' still belongs to the crowd! Researchers from the Massachusetts Institute of Technology (MIT) have demonstrated that as the crowd expands (the larger the number of members), the more likely it is to 'converge' exactly the information scattered in the community. even if each member only observes what is near them (within a narrow range).
Do you remember the story of four blind teachers touching elephants? If ' connected ', the 'thinking ' set of all four teachers will give an accurate 'look' for the elephant.
Imagine the brainpower of the network of hundreds of millions of people today (Facebook currently has over 500 million users). It is too early to talk about supercomputers that collect many ' cells ' similar to human brains, but ' collective intelligence ' or CI (Collective Intelligence) is not far away.
The first CI concept was introduced by Pierre Lévy in the book ' Collective Intelligence: Mankind's Emerging World in Cyberspace ' published in 1997. Pierre Lévy was ahead of the early age, when the Internet was not widespread, there were no ' 'effective tool for people to connect and contribute their intellect.
Recently a number of security solution vendors have been quick to use CI to detect malicious software. But CI used in these solutions is only in a narrow sense.
In the presentation of 'Information Technology in 2020: Building a Collective Intelligence ' in July 2010, Professor Srini Devadas of MIT's artificial intelligence and computer science laboratory gave a broader view: CI based on two pillars are cloud computing (cloud computing) and crowd computing (crowd computing). Cloud computing provides computing infrastructure and information available for everyone to access; Crowd computing analyzes and synthesizes information into transcendental intelligence.
' We are sinking in the sea of information, but lack wisdom. The world will belong to those who have the ability to synthesize the right information and in the right time . '(Consilience: The Unity of Knowledge, EO Wilson).
Same calculation on clouds
Technology has evolved to the point where it is easy for people to exploit anytime, anywhere. Social networks spread across the globe, connecting hundreds of millions of people, not only allowing instant discussions, debates and information exchange; but it also allows people to contribute to the implementation of complex projects that it is difficult for individual researchers or small groups to implement. This is the result of the convergence of many technological advances in areas such as network systems, smart devices, cloud computing, web and social networks.
 People can participate directly with feedback, reviews, or join the crowdsourcing market like Amazon Mechanical Turk; or can also participate indirectly with 'web surfing ' when searching, reading, shopping or playing online games. With hundreds of millions of networked users, the amount of information exchanged is enormous. How can we (and computers) exploit, analyze and aggregate this collective information? New generation Web platform with cloud computing can allow that.
People can participate directly with feedback, reviews, or join the crowdsourcing market like Amazon Mechanical Turk; or can also participate indirectly with 'web surfing ' when searching, reading, shopping or playing online games. With hundreds of millions of networked users, the amount of information exchanged is enormous. How can we (and computers) exploit, analyze and aggregate this collective information? New generation Web platform with cloud computing can allow that.
The figure is a model that illustrates 'the machine-person ' creating the magic - collective intelligence. Input raw data is a rich source of information on social networks based on Web 2.0 technology. Based services that knowledge Web technology (3.0) will harness billions of gigabytes of raw data and organize into ' quality ' data for processing and aggregation. This ' fine ' data will then be processed and evaluated by the human 'filter'. The results will produce specialized knowledge store repositories.
New computing platform brings human-machine relationship to a new level. People not only enter and consume information but also play a role in information processing (the term ' processor ' may need to be redefined).
This is the most interesting thing about crowd computing: people contribute to computational power. In other words, the human brain is treated as a processor in a distributed computing system, each of whom can perform a part (which can be small, simple) in a complex computing task.
Do you remember the SETI @ Home project over 10 years ago? This project calls for millions of users to contribute free computing computing resources (via screen saver software) to carry out a search for extraterrestrial intelligence. A form of crowdsourcing and crowd computing.
Extraterrestrial intelligence has not been found, but it is forecasted that in the next 10 years we will have . the world's intelligence.
With the development of Internet and cloud computing, a system of processing and synthesizing knowledge of user communities around the world is not unimaginable.
More extensive, do not limit cloud computing to servers (servers) only. Think of the ' computing cloud ' that includes a crowd of billions of smart devices (computing power that is even more powerful than the previous big computer) and the knowledge of billions of 'supercomputers ' (people ) globally.
With collective intelligence, what's impossible?
New web for crowd computing
Before the Web era, the last decade of the computer era (1980-1990) was mainly concerned with innovation in the 'surface ' of personal computers: desktops and computer user interfaces. The focus of this phase is to make computers easier to use with improvements such as Microsoft Windows, Macintosh, a more consistent user interface and integrated applications.
The first decade of the Web era ("Web 1.0", 1991-2000) focuses on infrastructure: Web core technologies and platforms such as HTML, HTTP, web servers, search engines, and technology trade and advertising, the basic architecture and business model of Web applications. The majority of Web investment in this decade has only been seen by developers.
In contrast, the second decade of the Web ("Web 2.0", 2001-2010) mainly focused on 'surface '. Many improvements are not necessarily technologies, but only design and user interface models to improve the user experience on the Web. In this decade people focused on models like AJAX, a collection of technologies and methods designed to make the site more intuitive, engaging and interactive.
One focus of Web 2.0 is the user-generated content, especially the "tagging" of the content for the content. Tagging has led to the concept of "folksonomies" (variations from ' taxonomy ') that only categorize and organize data through the user community.
The development of the Internet and social networks has led to an explosion of information on the Web, mostly unstructured. Keyword-based search engines provide the ability to search for this information, but only simple queries. Current Web search cannot match the exact query capabilities of the database. This is about to change.
Now people talk about the third decade of the Web ("Web 3.0", 2011-2020) shifting the focus back to the underlying platform. This decade will focus on upgrading the technical infrastructure and content of the Web, to make the Web work like a database.'Web knowledge' - a concept proposed by Nova Spivak that makes information on the web ' meaningful ', allowing the software to ' understand ' human knowledge.
Was this article helpful?
Your feedback helps us improve.
Related Articles
 Fog Computing - What is fog computing?7 minutes read
Fog Computing - What is fog computing?7 minutes read
 How to Crowd Surf6 minutes read
How to Crowd Surf6 minutes read
 Learn about Edge Computing: New boundary and border computing of the Web11 minutes read
Learn about Edge Computing: New boundary and border computing of the Web11 minutes read
 Quantum computing - a marathon, not a sprint contest!11 minutes read
Quantum computing - a marathon, not a sprint contest!11 minutes read
 Cloud computing - revolutionizing cheap computing with the Internet7 minutes read
Cloud computing - revolutionizing cheap computing with the Internet7 minutes read
 What is Serverless Computing?6 minutes read
What is Serverless Computing?6 minutes read
Reader Comments 0
Sign in with email or Google to join the discussion.