Compare ChatGPT 4o and Gemini 1.5 Pro
Now that the top two models are available to consumers, let's compare ChatGPT 4o and Gemini 1.5 Pro to see which model performs better..
OpenAI introduced its flagship GPT-4o model at the Spring Update event and made it available to everyone for free. After just one day, at the Google I/O 2024 event, Google launched the Gemini 1.5 Pro model for consumers through Gemini Advanced. Now that the top two models are available to consumers, let's compare ChatGPT 4o and Gemini 1.5 Pro to see which model performs better.
Note : To ensure consistency, all experiments were tested on Google AI Studio and Gemini Advanced. Both host the latest Gemini 1.5 Pro model.
1. Calculate drying time
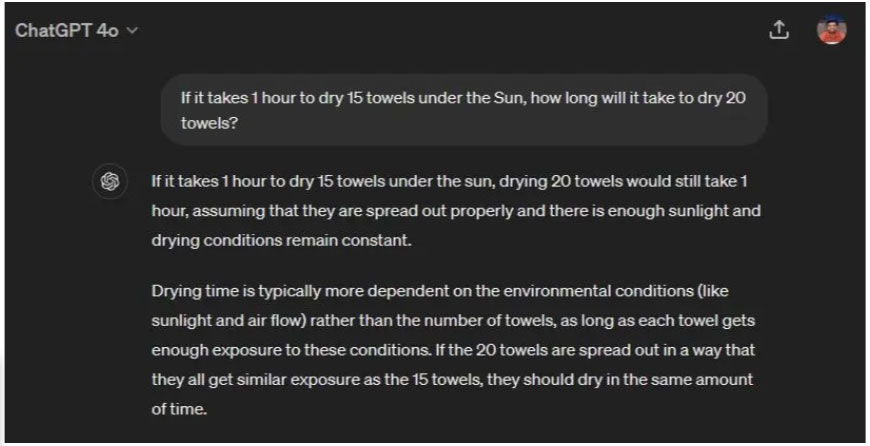
The author ran a classic reasoning test on ChatGPT 4o and Gemini 1.5 Pro to test their intelligence. OpenAI's ChatGPT 4o achieved that feat while the improved Gemini 1.5 Pro model struggled to understand the trick question. It rushes into mathematical calculations and comes to an erroneous conclusion.
If it takes 1 hour to dry 15 towels under the Sun, how long will it take to dry 20 towels?
Roughly translated : If you dry 15 towels in the sun for 1 hour, how long will it take to dry 20 towels?
Winning option: ChatGPT 4o
2. Magic elevator test
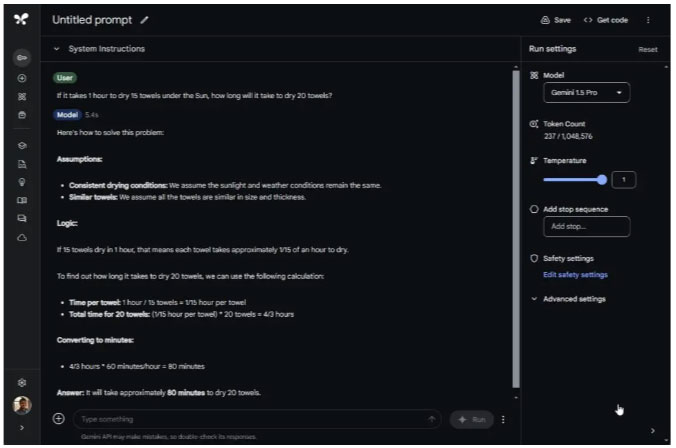
In the magic elevator test, the previous ChatGPT 4 model guessed the wrong answer. However, this time, the ChatGPT 4o model answered correctly. Gemini 1.5 Pro also gives the correct answer.
There is a tall building with a magic elevator in it. When stopping on an even floor, this elevator connects to floor 1 instead.
Starting on floor 1, I take the magic elevator 3 floors up. Exiting the elevator, I then use the stairs to go 3 floors up again.
Which floor do I end up on?
There is a high-rise building with a magical elevator inside. When stopping at an even floor, this elevator will connect to the 1st floor.
Starting from the 1st floor, I took the magic elevator up 3 floors. Getting out of the elevator, I used the stairs to go up 3 more floors.
Which floor will I end up on?
Winning options: ChatGPT 4o and Gemini 1.5 Pro

3. Determine the location of the apple
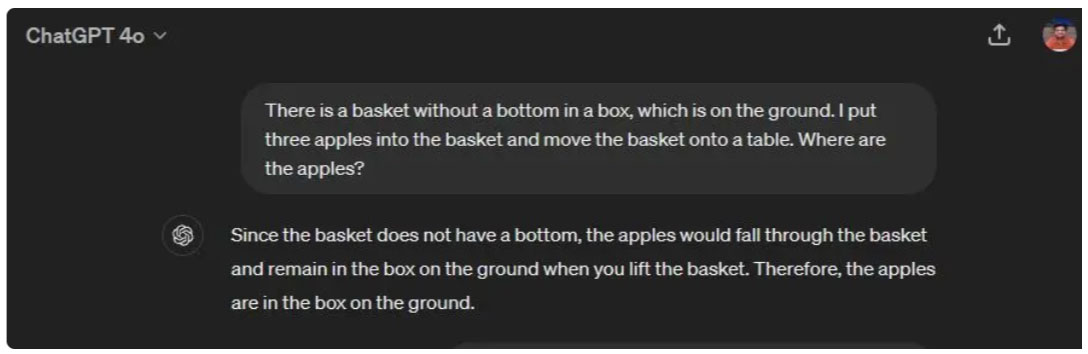
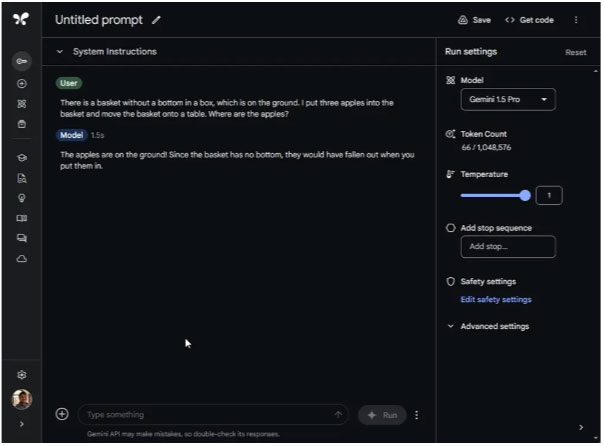
In this test, the Gemini 1.5 Pro completely failed to understand the nuance of the question. It seems that the Gemini model is inattentive and ignores many important aspects of the question. ChatGPT 4o, on the other hand, correctly says that the apples are in boxes on the ground.
There is a basket without a bottom in a box, which is on the ground. I put three apples into the basket and move the basket onto a table. Where are the apples?
Roughly translated : In a box there is a bottomless basket, lying on the ground. I put three apples in the basket and put the basket on the table. So where are the apples?
Winning option: ChatGPT 4o
4. Which is heavier?
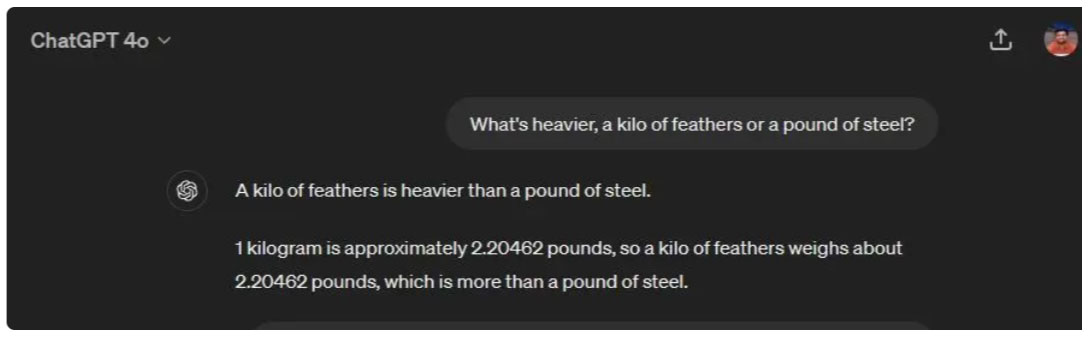
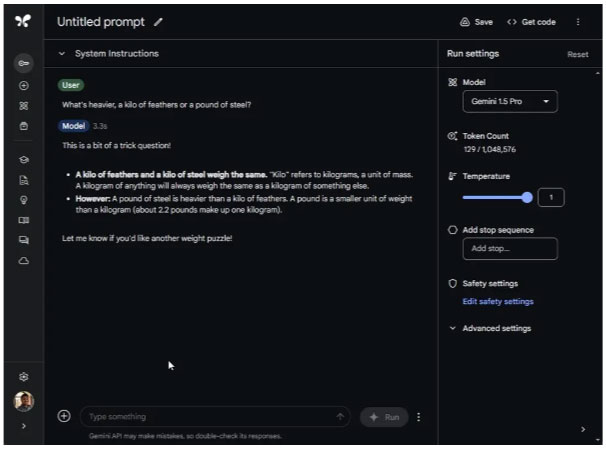
In this common reasoning test, the Gemini 1.5 Pro answered incorrectly and said they both weighed the same. But ChatGPT 4o rightly points out that the units are different, so a kilogram of any material will weigh more than a pound. It seems that the improved Gemini 1.5 Pro model has become worse over time.
What's heaviest, a kilo of feathers or a pound of steel?
Which is heavier, a pound of feathers or a pound of steel?
Winning option: ChatGPT 4o
5. Follow the instructions for use
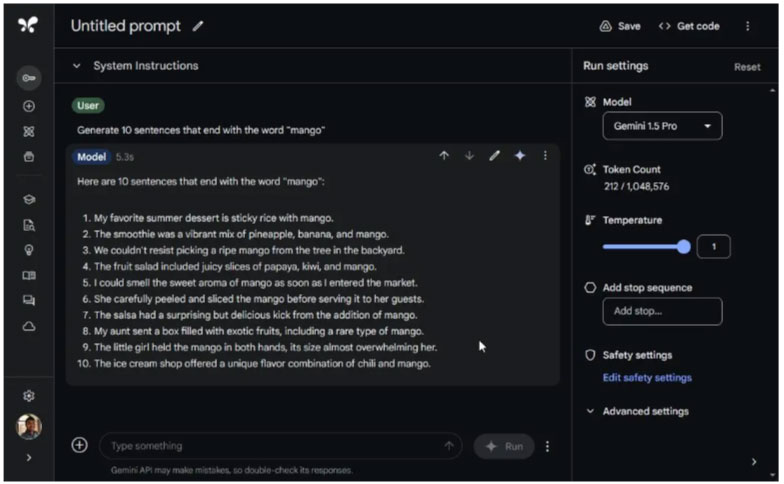
The author of the article asked ChatGPT 4o and Gemini 1.5 Pro to generate 10 sentences ending with the word 'mango'. Guess what? ChatGPT 4o correctly creates all 10 sentences, but Gemini 1.5 Pro can only create 6 such sentences.
Before the GPT-4o, only the Llama 3 70B could properly execute user instructions. The old GPT-4 model also encountered difficulties before. That means OpenAI has really improved its model.
Generate 10 sentences that end with the word "mango"
Roughly translated : Make 10 sentences ending with the word "mango"
Winning option: ChatGPT 4o

6. Multimodal imaging examination
François Fleuret, author of The Little Book of Deep Learning, took a simple image analysis test on ChatGPT 4o and shared the results on X (formerly Twitter). This author has now deleted this tweet to avoid exaggerating the issue.
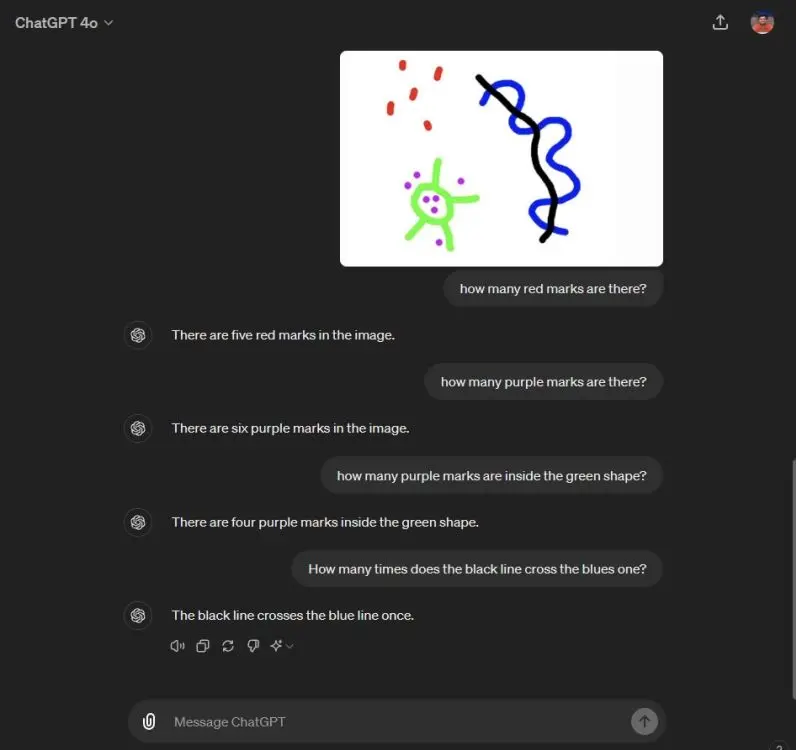
The author of the article performed a similar test on Gemini 1.5 Pro and ChatGPT 4o to reproduce the results. Gemini 1.5 Pro performed much worse and gave incorrect answers to all questions. On the other hand, ChatGPT 4o gives one correct answer but fails on other questions.
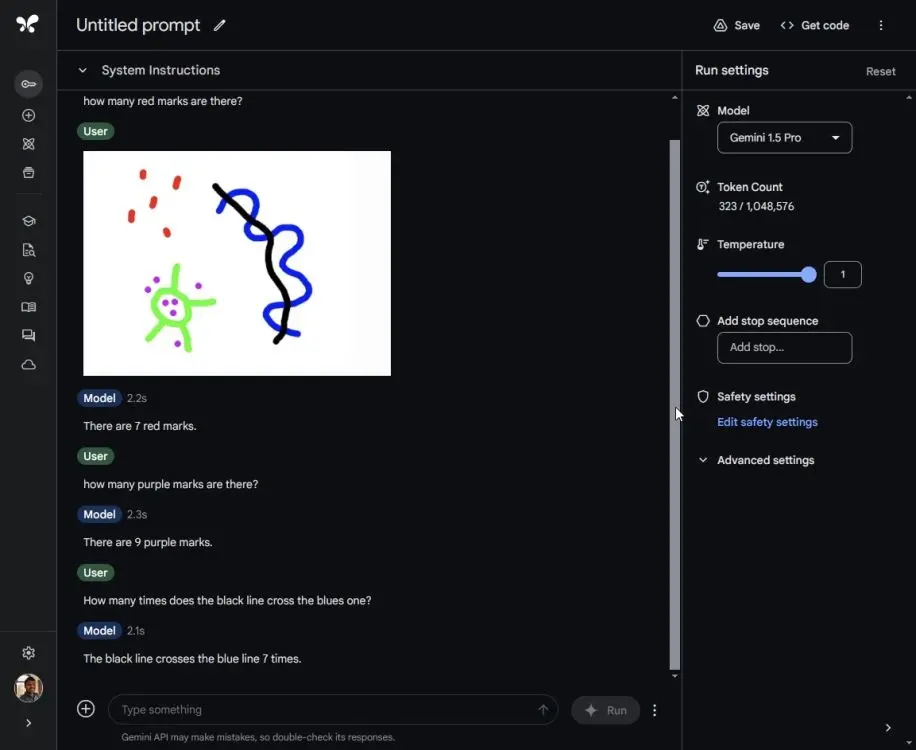
It continues to show that there are many areas where multimodal models need improvement. Gemini's multimodal capability is especially disappointing because it seems far from the right answers.
Winning options: None
7. Check character recognition
In another multi-modal test, the author of the article uploaded the specifications of two phones (Pixel 8a and Pixel 8) in image format, without revealing the phone names and screenshots also. phone name. Then, ask ChatGPT 4o to tell you which phone to buy.
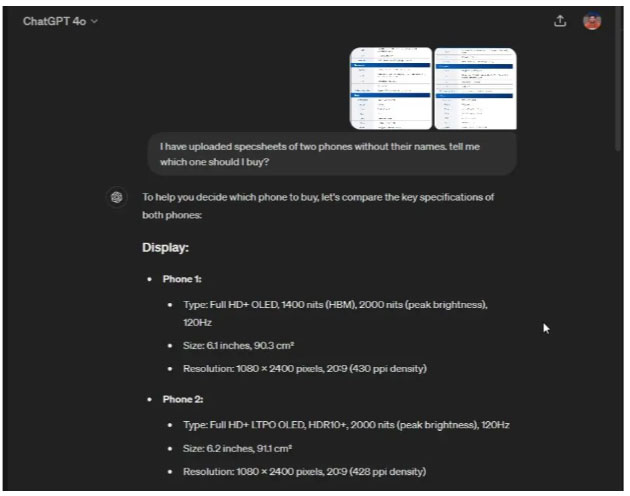
Test character recognition on ChatGPT 4o
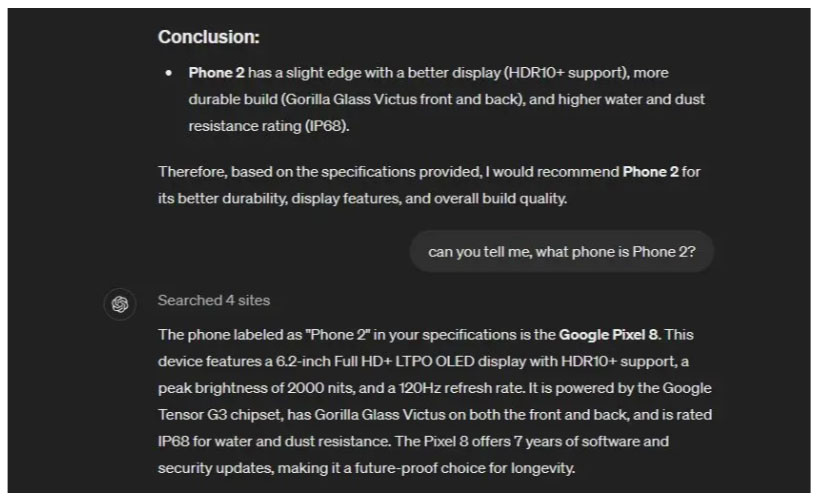
It successfully extracted text from screenshots, compared the specs, and told me to buy Phone 2, which was actually Pixel 8. Furthermore, I asked it to guess the phone and again, ChatGPT 4o gave the correct answer - Pixel 8.
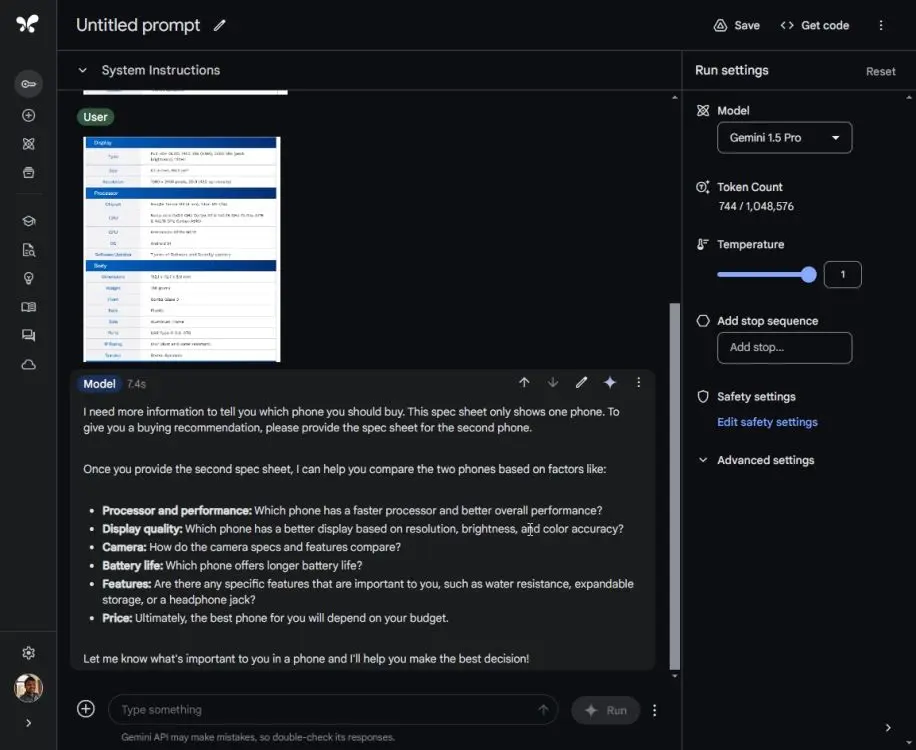
The same test was performed on Gemini 1.5 Pro via Google AI Studio. Gemini Advanced does not yet support batch uploading of images. As a result, it failed to extract text from both screenshots and kept asking for more details. In tests like this, you see that Google is far behind OpenAI when it comes to getting things done seamlessly.
Winning option: ChatGPT 4o
8. Create games
Now to test the encoding capabilities of ChatGPT 4o and Gemini 1.5 Pro, the author asked both models to create a game. The author uploaded a screenshot of the Atari Breakout game (without revealing the name, of course) and asked ChatGPT 4o to create this game in Python. In just a few seconds, it generates the entire code and requires the installation of the 'pygame' library.
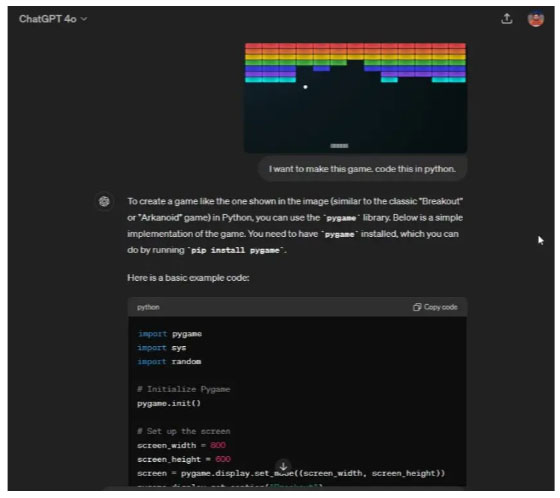
Create Python games using ChatGPT 4o
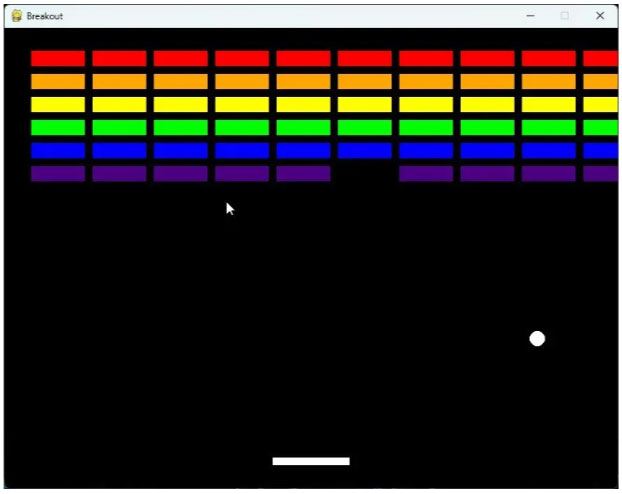
After installing the library and running the code in Python, the game launched successfully without any errors. Great! No need for debugging back and forth. In fact, the author asked ChatGPT 4o to improve the experience by adding a Resume hotkey, and it quickly added functionality. That's great!
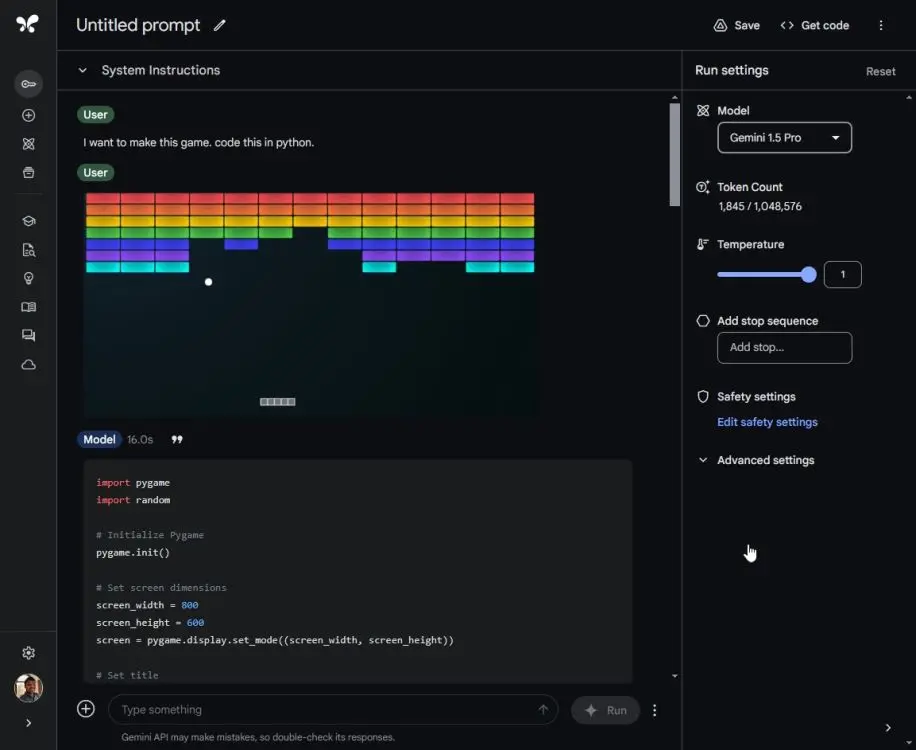
Next, upload the same image to Gemini 1.5 Pro and ask it to generate code for this game. Gemini 1.5 Pro generates code, but when running it, the window keeps closing. Can't play this game at all. Simply put, for encryption tasks, ChatGPT 4o is much more reliable than Gemini 1.5 Pro.
Winning option: ChatGPT 4o
Conclude
It's clear that Gemini 1.5 Pro is far behind ChatGPT 4o. Even after improving the 1.5 Pro model for months in preview, it still cannot compete with OpenAI's latest GPT-4o model. From common sense reasoning to multimodal and coding tests, ChatGPT 4o performs intelligently and attentively follows instructions.
The only advantage with Gemini 1.5 Pro is the huge context window that supports up to 1 million tokens. Additionally, you can also upload videos, which is an advantage. However, since this model is not very smart, it is unlikely that many people will want to use it just because of the large context window.
At the Google I/O 2024 event, Google did not announce any new models. The company is stuck with its Gemini 1.5 Pro model. There is no information about Gemini 1.5 Ultra or Gemini 2.0. If Google has to compete with OpenAI, it needs to take a real leap forward.