Table of Contents
Discover OmniVoice Studio, an open-source AI voice application that supports voice cloning, dubbing, dictation, and MCP workflows.
This means audio needs to be uploaded to an external system, the workflow is constantly dependent on the internet, and users also have to pay monthly subscription fees if they want to use it long-term. In the context of rapidly developing local AI, many people are starting to look for solutions that can run offline, keep data on their personal computers, and allow for deeper customization instead of relying entirely on cloud platforms.
That's also why OmniVoice Studio is noteworthy. It's an open-source desktop application that lets users process a wide range of AI voice tasks directly on their computer without sending data to an external server.
Interestingly, OmniVoice Studio is not simply a text-to-speech tool. This project is attempting to build a complete local AI voice ecosystem with many features previously only found on major commercial platforms.
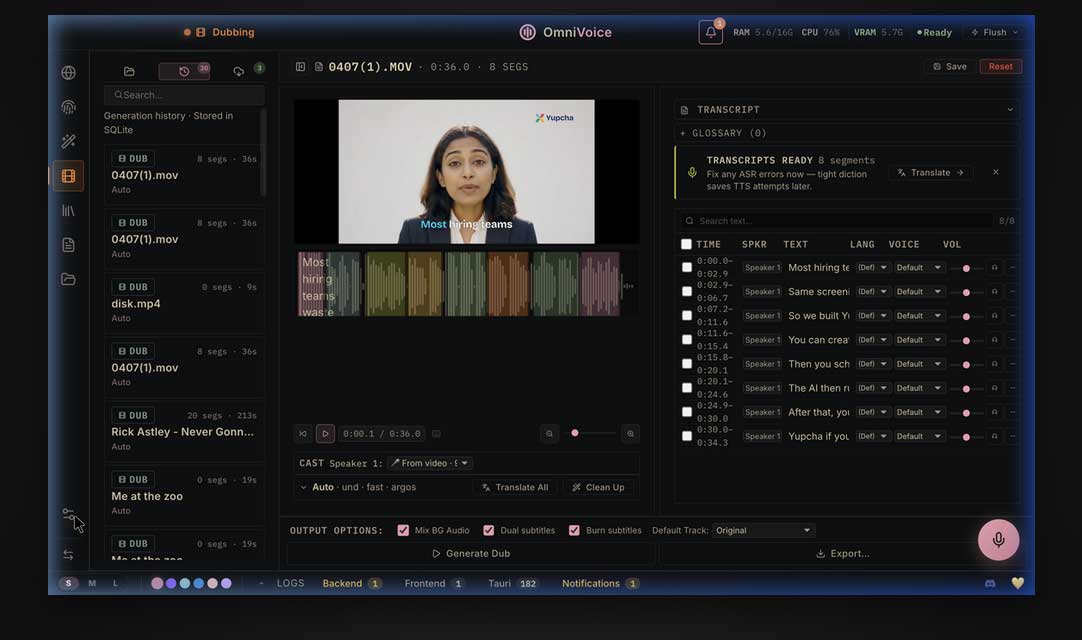
What can OmniVoice studio do?
What makes OmniVoice Studio stand out is that it consolidates many AI voice workflows into a single desktop application.
Perhaps the most noteworthy feature is voice cloning. The system can clone voices from just a few seconds of reference audio using zero-shot learning. This means the model doesn't need to be trained beforehand with that voice to produce a similar sound.
Beneath the surface, OmniVoice uses a diffusion-based TTS model to learn features from short audio clips and then synthesize new speech. According to the project documentation, the underlying engine supports over 600 different languages — a rather impressive number for a locally run open-source project.
In addition to cloning real voices, the system also supports 'voice design'. Instead of copying existing voices, users can create new voices by adjusting various factors such as age, gender, accent, speaking speed, pitch, or emotion. This is quite useful for creators who want to build their own narrator voices for videos, podcasts, or AI content automation workflows.
Another noteworthy feature is the ability to run video dubbing completely offline. Users simply enter the YouTube URL or select a local video, and the system will automatically transcribe the audio, translate the transcript, create new voiceovers, and then export them as a complete MP4 file.
The entire pipeline runs directly on the personal computer. This is quite different from most current AI dubbing platforms, which rely almost entirely on cloud processing.
Real-time dictation using 'AI overlay'
OmniVoice Studio also includes a built-in dictation widget that acts as a system-wide floating overlay.
On macOS, users can quickly activate it using the key combination: ⌘ + ⇧ + Space. Then, they can start speaking directly from any application.
The system will stream transcription in real-time and automatically insert the content into the app being focused on. This experience is quite similar to current commercial AI dictation tools, but the difference is that the entire processing still takes place locally instead of sending the audio to a cloud server.
For those who frequently write content, reply to emails, or take quick notes using voice commands, this is a highly practical feature.
Supports Batch Workflow and MCP integration
One of the things that makes OmniVoice Studio seem much more 'serious' than many other hobby projects is its ability to handle large workflows. The application lets you import dozens of videos into a Batch Queue and process them continuously in the background. Each job has its own progress tracking so users can monitor the entire pipeline from transcription to final video export.
Furthermore, the project includes a built-in MCP Server. This allows OmniVoice Studio to connect directly to Claude, Cursor, or any other MCP client. This is a very noteworthy detail because MCP is gradually becoming one of the most popular connection standards for modern AI agent workflows. This means OmniVoice Studio is not just a standalone desktop app, but can also function as part of a larger automation ecosystem.
Technically, OmniVoice Studio uses a React frontend that connects to a FastAPI backend. The backend currently offers nearly 100 API endpoints, uses Server-Sent Events for real-time streaming, and stores data via SQLite.
The machine learning component is built upon several popular open-source AI libraries. WhisperX handles speech recognition and word-level alignment, supporting approximately 99 languages for transcription. Meanwhile, Meta's Demucs is used to separate speech from background music, and Pyannote handles speaker diarization—identifying who is speaking in a multi-person audio recording.
Additionally, there's AudioSeal, an AI audio watermark technology that embeds invisible neural watermarks into generated audio for provenance and authentication of AI-generated content.
The entire desktop wrapper is built using Tauri — a popular Rust-based framework for cross-platform desktop applications.
Supports automatic GPU support and runs locally
One user-friendly aspect is that OmniVoice Studio requires almost no manual configuration.
The backend can automatically detect:
- CUDA for NVIDIA
- MPS for Apple Silicon
- ROCm for AMD GPUs
If VRAM is low, the system can also automatically offload part of the workload to the CPU instead of requiring the user to make too many adjustments. This is a very important detail because many open-source AI projects today are still difficult for the average user to install.
6 TTS engines in the same system
OmniVoice Studio now supports several different TTS engines via a plugin-based backend registry. The default engine is OmniVoice, which supports over 600 languages; other options include CosyVoice 3, MLX-Audio, VoxCPM2, MOSS-TTS-Nano, and KittenTTS.
Each engine has its own strengths. Some are optimized for Apple Silicon, some focus on real-time CPU inference, while others are more powerful at multilingual synthesis.
Interestingly, developers can easily add a custom TTS engine by subclassing TTSBackend with just a few dozen lines of Python code. This makes OmniVoice Studio more attractive to researchers or AI hobbyists who want to build their own voice workflows.
Why are local voice AI projects becoming increasingly important?
In recent years, the AI industry has seen a very clear trend: many AI workflows are beginning to shift from the cloud to local devices.
With voice AI, this is even more important because audio is often highly personal data. Local processing enhances privacy, reduces latency, avoids reliance on the internet, and allows businesses to better control their data.
Furthermore, the rapid development of small models and edge AI has also enabled many workflows that previously required cloud operation to now be processed directly on personal laptops or workstations. OmniVoice Studio is a clear example of this trend.
OmniVoice Studio may not yet be polished to the level of major commercial platforms like ElevenLabs. But interestingly, this project shows just how quickly local AI voice technology is advancing.
From voice cloning, AI dubbing, and dictation to MCP integration, many features that were once almost exclusively cloud-based are now starting to run completely offline.
For developers, AI enthusiasts, content creators, or businesses concerned about privacy, this could be one of the most noteworthy open-source projects currently in the field of voice AI.
Frequently Asked Questions
What should you know about omnivoice studio: an open-source ai voice solution worth trying?
Discover OmniVoice Studio, an open-source AI voice application that supports voice cloning, dubbing, dictation, and MCP workflows.
What can OmniVoice studio do?
What makes OmniVoice Studio stand out is that it consolidates many AI voice workflows into a single desktop application.
What should you know about real-time dictation using 'AI overlay'?
OmniVoice Studio also includes a built-in dictation widget that acts as a system-wide floating overlay.
Was this article helpful?
Your feedback helps us improve.
Related Articles
 How to Create AI Voices on OmniVoice3 minutes read
How to Create AI Voices on OmniVoice3 minutes read
 Why Should You Stop Using LM Studio and Switch to the Open-Source Alternative Jan?6 minutes read
Why Should You Stop Using LM Studio and Switch to the Open-Source Alternative Jan?6 minutes read
 How to Install Obs Studio in Ubuntu3 minutes read
How to Install Obs Studio in Ubuntu3 minutes read
 Mozilla Launched the First Open Source Voice Recognition Engine4 minutes read
Mozilla Launched the First Open Source Voice Recognition Engine4 minutes read
 S Code and VSCodium: Two 'Open-source' Versions, but How Different Are They6 minutes read
S Code and VSCodium: Two 'Open-source' Versions, but How Different Are They6 minutes read
 Can Open Source Technology Make Money?5 minutes read
Can Open Source Technology Make Money?5 minutes read
Reader Comments 0
Sign in with email or Google to join the discussion.